Massenspeicher
- Speichermedien
- Partitionierung der Festplatten
- Das Dateisystem
- Einführung von Unterverzeichnissen
- Hardlinks
- Softlinks
- Der Verzeichnisbaum
- Master-Boot-Record MBR
Es soll hier nicht um die Besonderheiten der einzelnen Filesysteme wie fat, vfat, ext2, ext3, ext4 usw. gehen, die Linux unterstützt, sondern um den grundsätzlichen Aufbau der Verzeichnisstruktur eines Linux-Systems. Da es viele unterschiedliche Varianten von Linux gibt, sollen die Darstellungen auch allgemein bleiben.
Speichermedien
Die Festplatte ist auch heute noch eines der wichtigsten Speichermedien in Computern. Sie können riesige Datenmengen speichern, sind kostengünstig und relativ schnell. Die Datenbits werden in Form von konzentrischen Kreisen als Magnetisierung auf den drehenden Platten gespeichert. Die Laufwerkselektronik moderner Festplatten lässt die riesige Speichermenge als Speicherblöcke mit einer Größe von 512Byte erscheinen, die einzeln durchnummeriert sind, beginnend mit 0 (LBA-Blockadressierung). Deshalb werden Festplatten auch als blockorientierte Geräte bezeichnet. Will man auf der Festplatte Daten speichern, dann kann man diese also in Form von 512Byte großen Teilen an die Festplattenelektronik senden und müsste sich irgendwo notieren, in welchen Blöcken die Daten abgespeichert wurden, also z.B.
- Brief an Oma ⇒ Block 1 und 2
- Adressenliste ⇒ Block 3 bis 11
- Urlaubsbild mit Klaus ⇒ Block 12 bis 1212
- Urlaubsbild mit Kristin am Strand ⇒ Block 1213 bis 2587
- Sonderzug nach Pankow als mp3 ⇒ Block 2588 bis 8219
- Firefox-Icon als png ⇒ Block 8219 bis 8260
- usw. usf.
Und so legt man die Daten blockweise auf der Festplatte ab, immer der Reihe nach. Sollte man eine Datei nicht mehr benötigen, kann man sie auf dem Zettel ja erst einmal einfach durchstreichen. Der Zettel könnte dann also später so aussehen...
- Brief an Oma ⇒ Block 1 und 2
Adressenliste ⇒ Block 3 bis 11- Urlaubsbild mit Klaus ⇒ Block 12 bis 1212
Urlaubsbild mit Kristin am Strand ⇒ Block 1213 bis 2587- Sonderzug nach Pankow als mp3 ⇒ Block 2588 bis 8219
- Firefox-Icon als png ⇒ Block 8219 bis 8260
- usw. usf.
Spätestens dann, wenn man mit der fortlaufenden Nummerierung beim letzten Block der Festplatte angekommen ist, bekommt man richtige Probleme, denn jetzt muss man sich genügend freie Stellen suchen, die von nicht mehr benötigten Daten stammen oder man müsste sich eine weitere Festplatte zulegen, obwohl eigentlich noch genug freier Platz auf der Platte ist, da bereits viele Dateien durchgestrichen sind und man diese Blöcke eigentlich für die neuen Daten nutzen könnte. Das bedeutet dann aber, dass auf dem Notizzettel mit der Zeit immer mehr Einträge in der Form auftauchen, wie bei "Bild vom Auto" zu sehen ist.
- Brief an Oma ⇒ Block 1 und 2
Adressenliste ⇒ Block 3 bis 11- Urlaubsbild mit Klaus ⇒ Block 12 bis 1212
Urlaugsbild mit Kristin am Strand ⇒ 1213 bis 2587- Sonderzug nach Pankow als mp3 ⇒ Block 2588 bis 8219
- Firefox-Icon als png ⇒ Block 8219 bis 8260
- usw. usf.
- Bild vom Auto ⇒ Block 3 bis 11, dann weiter Block 1213 bis 2587, und Block 8341 bis 8380 und Block 13567
Man muss die Daten also mit der Zeit immer häufiger auf Blöcke verteilen, die über die ganze Festplatte verstreut liegen. Die Daten werden also zunehmend fragmentiert. Wenn man sich nun überlegt, dass die Speicherkapazität einer Festplatte riesig ist, dann wird klar, dass der Notizzettel Millionen von Zeilen besitzen kann und das Zeilen bei großen Dateien mit starker Fragmentierung viele tausende Blocknummern besitzen können, dann wird klar, dass der Notizzettel irgendwann nicht mehr in die Wohnung passt und die Suche nach freien Blöcken Stunden dauern kann.
Dieses Problem wurde im Prinzip mit drei Unterschiedlichen Methoden gelöst, der Partitionierung der Festplatten, der Schaffung eines Dateisystems und der Einführung von UnterverzeichnissenPartitionierung der Festplatten
Partitionen sind Organisationsstrukturen auf der Festplatte. Mit der Partitionierung kann der Speicherraum einer Festplatte in bis zu 4 Blöcke aufgeteilt werden. Diese Blöcke sind die sogenannten primären Partitionen. Man kann auch drei primäre und eine erweiterte Partition anlegen, die dann in eine Vielzahl logischer Laufwerke aufgeteilt werden kann. Diese Blöcke sind voneinander unabhägig und können vom Betriebssystem dann wie eigenständige Laufwerke behandelt werden. Das hat verschiedenen Vorteile:
- Auf den einzelnen Partitionen können unterschiedlche Dateisysteme verwendet werden. Da viele Betriebssysteme ihr eigenes Dateisystem benutzen, kann man so mehrere Betriebssysteme auf einem Rechner installieren. Es kann auch sein, dass man spezielle Software nutzt, z.B. eine Datenbank, die ihr eigenes Dateisystem benötigt.
- Wenn es auf einer Partition zu einem Konflikt im Dateisystem kommt, hat das keine Auswirkungen auf die anderen Partitionen und verhindert so den totalen Datenverlust.
- Ist eine Partition gefüllt, hat das keine Auswirkungen auf die anderen Partitionen. Wenn also z.B. die Userdaten generell auf einer Partition gespeichert werden und das Betriebssystem selbst nutzt eine andere Partition, kann der Anwender das System durch Abspeicherung zu großer Datenmengen nicht gefährden.
- Jedes Dateisystem hat eine Maximalanzahl von Blöcken, die es unterstützt. Das hat zur Folge, dass das ganze Dateisystem auf der Festplatte eine Maximalgröße besitzt, die nicht überschritten werden kann. Wenn die Kapazitäten der Festplatten also anwachsen, kann man irgendwann nicht mehr die komplette Festplatte mit einem Dateisystem belegen. Die Partitionierung so großer Festplatten schafft da Abhilfe.
Welche Festplatten am Rechner verfügbar sind, kann man z.B. mit dem Tool fdisk testen. Den vollen Zugriff erhält man jedoch nur mit root-Login, da mit fdisk auch die Partitionierung vorgenommen werden kann.
Die Ausgabe von fdisk -l in einem root-Login sieht z.B. so aus:bash-4.1# fdisk -l Disk /dev/sda: 163.9 GB, 163928604672 bytes 255 heads, 63 sectors/track, 19929 cylinders, total 320173056 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0xf026f026 Device Boot Start End Blocks Id System /dev/sda1 * 63 1975994 987966 83 Linux /dev/sda2 1975995 104374304 51199155 7 HPFS/NTFS/exFAT /dev/sda3 104374305 108294164 1959930 82 Linux swap /dev/sda4 108294165 320159384 105932610 5 Extended /dev/sda5 * 108296213 171210772 31457280 83 Linux /dev/sda6 171212821 175407124 2097152 83 Linux /dev/sda7 175409173 179603476 2097152 83 Linux /dev/sda8 179605525 320159384 70276930 83 Linux Disk /dev/sdc: 4091 MB, 4091609088 bytes 63 heads, 62 sectors/track, 2045 cylinders, total 7991424 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x00000000 Device Boot Start End Blocks Id System /dev/sdc1 8192 7995391 3993600 b W95 FAT32 bash-4.1#
Linux hat hier zwei Festplatten aufgelistet, die unterschiedlich partitioniert sind.
Die erste Festplatte besitzt die Bezeichnung sda, mit einer Größe von 164GB. Die Angabe /dev/sda ist der Dateiname der Pseudodatei mit der der Kernel diese Festplatte im Verzeichnis /dev darstellt. Über diese Gerätedatei kann auf die gesamte Festplatte zugegriffen werden, so als wäre es der oben beschriebene lineare Speicherbereich mit der Adressierung durch Blocknummern. Diese Gerätedatei wird deshalb auch genutzt, um die Partitionen auf einer Festplatte anzulegen. Wenn die Platte sda also partitioniert werden soll, dann z.B. mit dem Kommando fdisk /dev/sda.
Der Zugriff auf diese Gerätedatei ist also sehr hardwarenah und man könnte die Festplatte darüber in der oben beschriebenen Weise auch nutzen. Für den Anwender ist ein solcher Zugriff auf die Platte eher ungünstig und er würde wohl eher Schaden anrichten. Deshalb hat auch nur root Zugriff auf diese Datei und der sollte auch Wissen, was er tut.
Die Festplatte im Beispiel ist in drei primäre Partitionen /dev/sda1, /dev/sda2 , /dev/sda3 und eine erweiterte Partition /dev/sda4 partitioniert, wobei die erweiterte Partition in vier weitere Laufwerke /dev/sda5-8 aufgeteilt ist. Die Bezeichner /dev/sda1.../dev/sda8 sind wieder die Namen der Gerätedateien, mit denen der Kernel diese als separate Laufwerke abbildet.
Die zweite Festplatte sdc besitzt nur eine einzige Partition /dev/sdc1. Es handelt sich dabei um eine Kamera mit Flash-Karte, die an das System über USB angeschlossen ist. Viele Flash-Karten, USB-Sticks etc. ähneln in ihrer Organisationsstruktur den klassischen und können auch partitioniert werden.
Auf diese Gerätedateien hat der Normaluser natürlich ebenfalls keinen Zugriff, denn es handelt sich ja nur um Bereiche von /dev/sda. Auf diese Geräte greift die Software des Dateisystems zu, das für die Organisation der einzelnen Blöcke der Partition zu Dateien und Verzeichnissen verantwortlich ist. Diese Software erstellt dann den Verzeichnisbaum auf den der User dann zugreifen kann.Das Dateisystems
Um nicht, wie oben beschrieben, in der Zettelflut zu versinken, wird die Verwaltung der Blöcke einer Partition einem Dateisystem übertragen. Davon gibt es unzählige, wie FAT, FAT32, VFAT, minix, ext2, ext3, ext4 und und und ..... Ich will hier auch nicht näher auf Einzelne eingehen, sondern nur kurz umreißen, wie das obige Problem im Ansatz gelöst werden kann.
Das Dateisystem soll viele Aufgaben erfüllen, wie z.B.- den Speicherplatz auf der Partition verwalten
- für die Daten freie Blöcke auf der Partition finden
- verwalten, welche Blöcke und in welcher Reihenfolge eine Datei bilden
- den Dateien verschiedene Attribute zuordnen, z.B. einen Namen einen Zeitstempel, Informationen über den Besitzer und Zugriffsrechte etc.
- gute Performance und wenig Systemlast erzeugen
- hohe Robustheit gegen Schreibfehler besitzen, ein unerwarteter Stromausfall während eines Schreibvorgangs soll nicht nicht das gesamte Dateisystem unbrauchbar machen
- eventuell die Daten durch Verschlüsselung sichern
- und vieles mehr....
Nun will ich also kurz umreißen, wie eine Lösung für zumindest die ersten vier Forderungen aussehen kann und so auch von einer Reihe von Dateisystemen umgesetzt wird. Ich will mich dabei auf kein bestimmtes Dateisystem beziehen und nicht allzusehr ins Detail gehen. Es handelt sich also nur um eine prinzipielle Darstellung, vieles wird man jedoch wiederfinden, wenn man sich mit seinem Dateisystem genauer beschäftigt.
Der Lösungsansatz besteht darin, die ganzen Verwaltungsinformationen zusammen mit den Daten ebenfalls auf der Festplatte zu speichern (wer hätte das gedacht). Nehmen wir an, dass die Festplatte neu ist und partitioniert wurde. Wir haben nun fortlaufend Blöcke von 512Byte zur Verfügung, die einzeln durch eine Indexnummer von 0 bis zu einem Endwert x durchnummeriert sind und über diese Nummer auch über die Festplattenelektronik angesprochen werden können. Für das Dateisystem legen wir nun folgendes fest:- In jedem Block werden die letzten 2Bytes reserviert, in denen keine Daten abgespeichert werden. Diese zwei Bytes werden benutzt, um eine Blocknummer aufzunehmen. In diesen zwei Bytes können die Hexzahlen von 0000h bis ffffh gespeichert werden, das sind die Nummern von 65536Blöcken. Da jeder Block eine Speicherkapazität von 512Bytes besitzt, kann dieses Dateisystem also Partitionen mit einer Maximalgröße von 65536*512Byte=33554432Byte, also rund 32MB verwalten. Das ist nicht viel, aber es geht ja nur ums Prinzip und wie viele Bytes ich reserviere, ist letztendlich Verhandlungssache.
- Im ersten Block 0 der Partition wird durch das Dateisystem eine Datei angelegt, nennen wir sie INHALT, die das Inhaltsverzeichnis der Partition enthält. In diese Datei wird das Dateisystem für jede Datei die abgespeichert werden soll, einen Name eintragen, ein Flag und die Nummer des ersten Blocks in dem die Daten der Datei abgespeichert wurden. Der Name soll aus maximal 7Zeichen bestehen, belegt also 7Byte, für das Flag reservieren wir ein Byte und die Blocknummer benötigt 2Bytes. Damit könnte man in dem Block 0 der Partion insgesamt 51Dateieinträge unterbringen. In den letzten zwei Bytes des Blocks 0 wird eine 0 eingetragen.
- In einem Block werden immer nur die Daten gespeichert, die zu genau einer Datei gehören. Das bedeutet, wenn eine Datei z.B. nur 3Byte enthält wird dafür trotzdem ein kompletter Block belegt, die restlichen 507Bytes bleiben eben einfach leer.
- Ist die Datei größer als 510Byte, dann wird die gesamte Datei gesplittet. In den ersten verfügbaren freien Block werden die ersten 510Byte der Datei abgelegt. In den letzten zwei Bytes dieses Blocks wird die Nummer des nächsten freien Blocks eingetragen und in dem Block werden dann die nächsten 510Byte abgelegt. Das geht so lang, bis das letzte Datenstück in einem Block gespeichert wurde und hier wird in die letzten 2Byte die Nummer 0 eingetragen und markiert damit das Ende der Datei. Die einzelnen Blöcke der Datei sind also über die Nummer in den letzten 2Bytes jedes Blocks miteinander in der richtigen Reihenfolge verkettet.
Jetzt wird auf der Partition das Dateisystem erzeugt. Genau genommen werden jetzt die notwendigen Verwaltungsinformationen in die Blöcke eingetragen. Da die Partition ja noch leer ist, werden nun alle Blöcke zu einer "leeren" Datei verkettet. In die letzten 2Bytes des ersten Blocks wird also die Nummer 2 eingetragen, in den zweiten Block die Nummer 3 usw. Im letzten Block wird die Nummer 0 als Kennung des Dateiendes abgespeichert. Danach wird im Inhaltsverzeichnis im Block 0 der erste Eintrag erzeugt, und zwar:
Datei INHALT im Block 0 Dateiname Flag Nummer des
ersten BlocksLEER 0 01 Auf der Festplatte sieht das Ganze dann so aus:

Nun soll eine Datei "Datei1" im Dateisystem abgespeichert werden. Das Dateisystem folgt dabei einem einfachen Algorithmus:
• Start • Lies aus der Datei INHALT im Block 0 die Startblocknummer der Datei .LEER aus. • Erzeuge in der Datei INHALT einen neuen Eintrag mit dem Namen der neuen Datei "Datei1" und trage die Blocknummer dort als Startblock der Datei ein. • Speichere 510Bytes der neuen Datei in diesem Block ab. • SOLANGE die neue Datei noch nicht vollständig geschrieben wurde, MACHE • Lies aus dem aktuell geschriebenen Block die nächte Blocknummer aus den letzten 2Bytes des Blockes aus. • Speichere bis zu 510Bytes der neuen Datei in diesem nächsten Block. • Lies aus den letzten 2Bytes des aktuellen Blocks die nächste Blocknummer aus und speichere dafür die 00 dort ab. • Trage die gelesene Nummer als erste Blocknummer der Datei .LEER in INHALT ein. • Fertig Danach hat die Verkettung der Blöcke auf der Festplatte die folgende Strucktur:

Die neue Datei "Datei1" belegt zwei Blöcke, die der Kette der Datei .LEER entnommen wurden. Die neue Datei besitzt nun als erste Blocknummer die, die die Datei .LEER vorher hatte. Dann wurden die Kette durchlaufen und die Daten der neuen Datei in diesen verketteten Blöcken gespeichert, bis alle Daten geschrieben waren. Aus diesem letzten Block wurde aus den letzten 2Bytes die Blocknummer des nächsten Blocks der Datei .LEER ausgelesen und als neuer Startblock für .LEER in INHALT eingetragen. Danach wurden in diesen letzten Block der neuen Datei die Endkennung 00 in die letzten 2Bytes des Blocks eingetragen. Die Blocknummer 00 wird hier als Endkennung verwendet, da der Block 0 niemals als nächster verketteter leerer Block vorkommen kann, denn im Block 0 ist ja INHALT gespeichert.
Genauso wird nun mit jeder neuen Datei verfahren, die abgespeichert werden soll, verfahren.
Als nächste soll die Datei "Datei2" gespeichert werden, die nur einen Block belegt. Da die Datei so kurz ist, wird die SOLANGE-Schleife des Algorithmus nicht durchlaufen. Die Verkettung hat nun die folgende Form: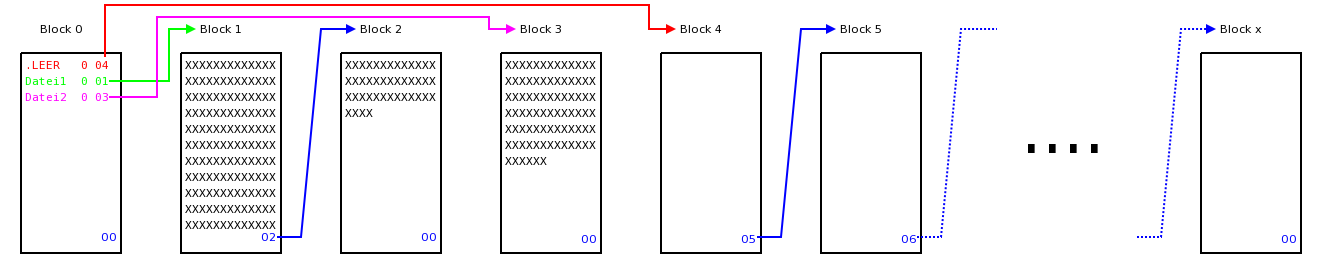
Es wurde also ein weiterer Block vom Anfang der Kette .LEER entfernt und für die neue Datei benutzt.
Nun soll die Datei "Datei1" wieder gelöscht werden. Das Dateisystem muss nun eigentlich nichts anderes tun, als die Startblöcke der Dateien "Datei1" und .LEER aus INHALT auszulesen. Dann beginnt es im Startblock der Datei "Datei1" und liest am Ende des Blocks die nächste Blocknummer aus und liest in dem Block wieder die letzten 2Bytes aus usw. usf., biss das Ende der Kette erreicht ist und die 00 gelesen wird. An dieser Stelle wird die Startblocknummer der Datei .LEER eingetragen und dann in der Datei INHALT die Startblocknummer der Datei "Datei1" als neue Startblocknummer der Datei .LEER eingetragen. Anschließend wird noch der Eintrag der Datei "Datei1" in INHALT gelöscht. Damit wurden die beiden verketteten Blöcke der ursprünglichen Datei "Datei1" an den Anfang der Kette der Datei .LEER eingefügt.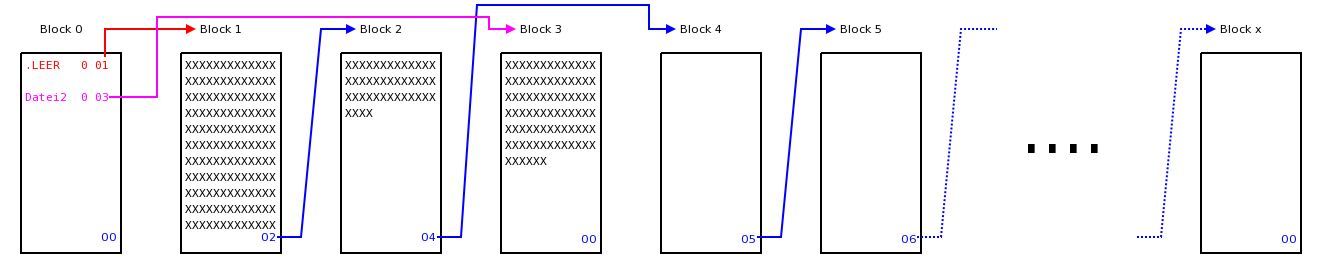
Mit diesen beiden einfachen Methoden zum Schreiben und Löschen von Dateien kann das Dateisystem nun die gesamte Partition verwalten. Das Dateisystem weist jeder Datei die angelegt werden soll automatisch freie Blöcke zu und muss diese nicht erst suchen, denn sie befinden sich ja alle in der Pseudodatei .LEER und können aus dieser entnommen werden. Beim Löschen werden die verketteten Blöcke der zu löschenden Datei einfach wieder in die Kette .LEER eingefügt. Der zentrale Anlaufpunkt ist also immer die Datei INHALT im ersten Block der Partition, von dem sich das ganze Dateisystem aufbaut.
Diese einfache Verwaltung kommt jedoch zustande, weil ein Block auch immer nur die Daten genau einer Datei aufnimmt. Es wird also bewusst Platz verschwendet!! Man muss sich also folgendes klar machen, wenn ich lauter winzige Dateien von 51Byte auf der Festplatte speichere, dann befinden sich in allen Blöcken der Festplatte nur 51Byte, obwohl sie 510Byte aufnehmen könnten! Die Festplatte hätte also 10% der maximal möglichen Speichermenge aufgenommen und das Dateisystem würde melden "Festplatte voll!". Viele moderne Dateisysteme, wie auch ext ziehen sogar 2, 4 oder meist 8 Blöcke zu einer logischen Einheit zusammen, was bedeutet, dass eine Datei also einen Platz von mindestens 4096Bytes belegt. Das nimmt man in Kauf, weil die Alternative viel schrecklicher wäre. Wenn z.B. ein Datenblock immer vollständig ausgenutzt werden soll, dann müsten zusätzliche Verwaltungsinformationen abgespeichert werden, in welchem Block und an welcher Stelle in dem Block eine Datei beginnt und wo sie wieder endet. Gerade bei kleinen Dateien könnten sich ja mehrere in einem Block befinden, diese Informationen muss das Dateisystem ja irgendwo abspeichern und das würde immer mehr Platz beanspruchen je kleiner die Dateien sind. Letztendlich wäre der Speicherbedarf an reiner Verwaltungsinformation noch höher als die Menge der gespeicherten Daten. Außerdem ist das "Herausschneiden" der Daten einer Datei aus den Datenblöcken für die CPU aufwändiger, das Dateisystem hätte also weniger Performance. Man hätte also nichts gewonnen. Man kann also nur versuchen, einen sinnvollen Kompromiss zu finden, zwischen Performance, Größe der Festplatte und der Größe der Dateien mit denen man arbeitet. Die ext-Dateisysteme vermischen Daten- und Verwaltungsinformationen auch nicht, sie werden in separaten Blöcken gespeichert, den Inodes, die dann die Verwaltungsinformationen der Dateien enthalten. Dadurch ist die Verarbeitung der Inforamationen effizienter. Der Hauptknotenpukt wie hier INHALT ist der Superblock, von dem mehrere Kopien auf der Partition gespeichert werden.
Es ist noch etwas wichtiges zu sehen, wenn eine Datei gelöscht wird, dann bedeutet das im Allgemneinen nicht, dass die Daten wirklich vernichtet werden. Da eigentlich nur Blocknummerneinträge verändert werden, sind die Daten weiterhin in den einzelnen Blöcken gespeichert. Das hat jetzt nichts mit dem öminösen "Papierkorb" zu tun, dabei handelt es sich genau genommen um ein spezielles Verzeichnis (zu denen kommen wir gleich), in das die Dateien abgelegt werden, nein selbst wenn dieser Papierkorb gelöscht wird, liegen die Daten physisch immer noch auf der Festplatte vor. Die meisten Dateisysteme verzichten aus Gründen der Performance auf das wirkliche Überschreiben der Daten beim Löschen. Unter Linux benutzt man zum Löschen von Dateien das Kommando rm. Will man die Daten wirklich vernichten, die Blöcke also überschreiben, sollte man z.B. shred verwenden.
Es ist ja so, dass selbst das Speichern einer neuen Datei die ursprünglichen Daten in den Blöcken nicht vollständig vernichten muss. Nehmen wir dazu an, dass in der Partition nun eine weitere Datei "Datei3" gespeichert wird. Sie soll weniger als 510Bytes enhalten. Die Verkettung der Blöcke sieht dann so aus: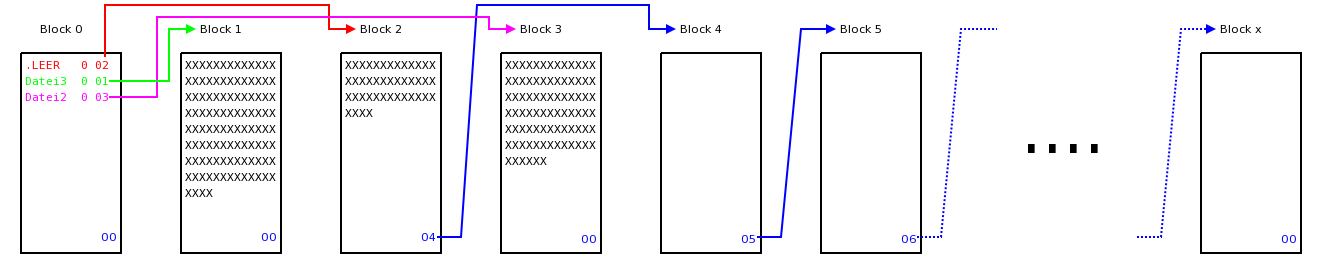
 Nun gut.
Es geht ja um eine vereinfachte Darstellung und einen Punkt habe ich noch nicht angesprochen, und zwar die unvollständig gefüllten Blöcke.
Wenn jetzt der letzte Block einer Datei nicht 510Byte lang ist, woran erkennt das Dateisystem beim Lesen der Datei wo Schluss ist?
Man kann ja nicht die restlichen Bytes einfach mit anhängen oder mit Nullen füllen, denn das würde die Datei verändern und könnte fatale Folgen haben.
Deshalb müssen natürlich in jedem Block noch weitere Verwaltungsinformationen, außer der 2Byte am Ende des Blockes für die Verkettung, gespeichert werden.
Es werden also zusätzliche Bytes reserviert, so z.B. für einen "Füllstandsanzeiger" in dem abgespeichert wird, bis zum wievielten Byte in dem Block es sich um aktuelle Daten handelt.
Damit kann das Dateisystem erkennen, ob der komplette Block von aktuellen Daten belegt ist oder nur ein Teil.
Für den Block 1 unserer Partition bedeutet das, das am Ende das Blockes immer noch Daten der Datei "Datei1" zu finden sind, da die Datei "Datei1" den Block vollständig belegt hatte, die "Datei3" aber weniger Platz in dem Block belegt.
Im Bild links habe ich mal angenommen, dass die Datei3 nur 300Bytes des Blocks belegt, in dem restlichen Teil des Blockes befinden sich noch Daten der ursprünglich dort gespeicherten Datei1.
Nun gut.
Es geht ja um eine vereinfachte Darstellung und einen Punkt habe ich noch nicht angesprochen, und zwar die unvollständig gefüllten Blöcke.
Wenn jetzt der letzte Block einer Datei nicht 510Byte lang ist, woran erkennt das Dateisystem beim Lesen der Datei wo Schluss ist?
Man kann ja nicht die restlichen Bytes einfach mit anhängen oder mit Nullen füllen, denn das würde die Datei verändern und könnte fatale Folgen haben.
Deshalb müssen natürlich in jedem Block noch weitere Verwaltungsinformationen, außer der 2Byte am Ende des Blockes für die Verkettung, gespeichert werden.
Es werden also zusätzliche Bytes reserviert, so z.B. für einen "Füllstandsanzeiger" in dem abgespeichert wird, bis zum wievielten Byte in dem Block es sich um aktuelle Daten handelt.
Damit kann das Dateisystem erkennen, ob der komplette Block von aktuellen Daten belegt ist oder nur ein Teil.
Für den Block 1 unserer Partition bedeutet das, das am Ende das Blockes immer noch Daten der Datei "Datei1" zu finden sind, da die Datei "Datei1" den Block vollständig belegt hatte, die "Datei3" aber weniger Platz in dem Block belegt.
Im Bild links habe ich mal angenommen, dass die Datei3 nur 300Bytes des Blocks belegt, in dem restlichen Teil des Blockes befinden sich noch Daten der ursprünglich dort gespeicherten Datei1.Einführung von Unterverzeichnissen
Das Dateisystem hat jetzt noch zwei Probleme.
Im ersten Block des Dateisystems ist nur Platz für insgesamt 51 Dateieinträge, das reicht bei weitem nicht aus. Das Problem ist jedoch schnell gelöst, indem sich die Datei INHALT einfach genauso verkettet, wie die anderen Dateien auch. Wenn der erste Block gefüllt ist, wird einfach aus der Kette .LEER ein Block entnommen und mit dem ersten Block verkettet usw.
Das zweite Problem ist, dass auf großen Festplatten Platz für sehr viele Dateien ist. Das Inhaltsverzeichnis wird also entsprechend lang und unübersichtlich und irgendwann gehen einem die Namen aus, denn jede Datei muss in INHALT ja einen eindeutigen Namen besitzen. Deshalb erfand man etwas später die Unterverzeichnisse. Bei einem Unterverzeichnis handelt es sich um eine Datei, die fast genauso aufgebaut ist, wie die Datei INHALT im ersten Block der Partition. Das Dateisystem legt diese Verzeichnisdatei, genau wie jede andere Datei an, kennzeichnet sie beim Eintragen des Namens in INHALT aber durch ein Flag, sagen wir 1. Ist also in INHALT eine Datei mit dem Flag 0 gekennzeichnet, dann handelt es sich um eine Datei, die Daten enthält. Ist sie mit dem Flag 1 gekennzeichnet, dann handelt es sich um ein Unterverzeichnis, in das das Dateisystem nun die Namen und Verkettungen weiterer Dateien ablegen kann. Auf gleiche Weise können in den Unterverzeichnissen die Namen weiterer Unterverzeichnisse abgelegt werden. Der einzige Unterschied zu INHALT ist, dass es keine Kette .LEER gibt. Leere Blöcke werden immer in die Kette .LEER eingefügt und entnommen, die in INHALT im ersten Block verwaltet wird.
Das bedeutet also, dass die Verzeichnisstruktur auf einer Partition eine Wurzel (root) besitzt, die der Ausgangspunkt des gesamten Dateisystems der Partition darstellt und wo die freien Blöcke verwaltet werden. Unterverzeichnisse sind speziell gekennzeichnete Dateien die nur eine logische Struktur der Dateinamen widerspiegeln, die mit der Anordnung der Dateien auf der Festplatte im Prinzip überhaupt nichts zu tun hat. Die einzelnen Datenblöcke von Dateien, Unterverzeichnissen (also Dateien) und INHALT (wenn sie um weitere Blöcke erweitert wurde) liegen nach einiger Zeit in bunt gemischter Reihenfolge durcheinander, nur über ihre Blocknummern verknüpft. Für die gespeicherten Daten ist das im Prinzip unerheblich, da das Dateisystem die Daten durch die Verkettungen immer wieder reproduziert. Es ist also offensichtlich falsch zu glauben, dass ein Unterverzeichnis irgendein bestimmter Bereich auf der realen Festplatte ist.Hardlinks
Unter Links versteht man Dateieinträge, die auf die selbe Datei verweisen. Das ist eine sehr effiziente Methode, wenn eine identische Datei an mehreren Stellen im Verzeichnisbaum sichtbar sein muss. Nehmen wir z.B. an, dass 100User eine Software verwenden, die eine Konfigurationsdatei im home-Verzeichnis erwartet und die der Administrator anlegen und pflegen muss. Man könnte nun in jedes Homeverzeichnis eine solche Datei hineinkopieren. Wenn in dieser Datei jedoch eine Änderung vorgenommen werden soll, dann wird der Arbeitsaufwand unter Umständen enorm ansteigen. Links helfen hier, denn man könnte nun einfach 100 Links in den Home-Verzeichnissen anlegen, die auf eine einzige Datei verweisen. Damit können diese Einstellungen in der einen Datei vorgenommen werden und alle User hätten über die Links den gewünschten Zugang zu der Datei.
Es gibt grundsätzlich zwei Arten, die Hardlinks und die Softlinks. Bei Hardlinks handelt es sich um Dateieinträge in Verzeichnissen, die auf die selbe Startblocknummer (bei ext also auf die selbe Inode) verweisen. Auf das oben beschriebene Beispiel eines Dateisystems würe das Anlegen eines Hardlinks "Datei4", der auf die Datei "Datei3" zeigen soll bewirkt, dass ein weiterer Verzeichniseintrag erzeugt wird, der ebenfalls auf die Startblocknummer 1 zeigt.

Unter den beiden Dateinamen wird auf die selbe Datei zugegriffen, es erscheint nur so, als ob zwei identische Dateien vorliegen. Unter Linux legt man solche Links mit dem Kommando ln an. Da die beiden Einträge direkt mit der Startblocknummer codiert werden, kann man solche Hardlinks nur innerhalb einer Partition setzen, es ist nicht möglich einen Hardlink von einer Datei einer Partition in den Verzeichnisbaum zu legen, der auf einer anderen Partition liegt. Innerhalb einer Partition kann man die Hardlinks jedoch frei über Verzeichnisse hinweg legen. Die Dateien besitzen einen Zähler, der die Anzahl der Hardlinks die auf diese Datei zeigen, abspeichert. Wird ein Dateieintrag (wie oben z.B. Datei3 oder Datei4) gelöscht, so wird nur der Verzeichniseintrag entfernt. Es ist also nicht so, dass z.B. Datei3 die "Originaldatei" ist. Wird nun also z.B. Datei3 gelöscht, so bleibt die Datei immer noch unter dem Namenseintrag Datei4 erhalten. Erst wenn der letzte Namenseintrag auf eine Datei gelöscht wird, werden die Blöcke wieder in die Kette .LEER eingefügt.Softlinks
Ein Softlink ist eine spezielle Datei, die einen Namensverweis auf eine andere Datei enthält. In dieser Datei ist also abgespeichert, wo sich die verlinkte Datei im Verzeichnisbaum befindet. Dazu wird in der (Softlink)-Datei der Pfad und der Name der Zieldatei abgelegt. Die Pfadangabe kann dabei absolut oder auch relativ sein. Da es sich hierbei nicht um eine harte Verlinkung mit Blocknummern sondern nur um eine symbolische Verlinkung auf die Zieldatei handelt, kann man solche symbolischen Links auch über Partitionsgrenzen hinweg anlegen. Im Gegensatz zu Hardlinks bleibt hier jedoch die Zieldatei die "Originaldatei". Das bedeutet, wird ein Softlink gelöscht, so hat das keine Auswirkungen auf die Zieldatei. Wird jedoch die Zieldatei gelöscht, so bleiben die Softlinks zwar erhalten, zeigen aber auf eine nicht mehr existierende Datei.
Der Verzeichnisbaum
bash-4.1$ ls -al / insgesamt 116 drwxr-xr-x 23 root root 4096 Feb 12 14:21 . drwxr-xr-x 23 root root 4096 Feb 12 14:21 .. drwx------ 1 root root 12288 Jul 25 20:32 WinXP drwxr-xr-x 2 root root 4096 Apr 30 2007 bin drwxr-xr-x 3 root root 4096 Nov 10 2011 boot drwxr-xr-x 3 root root 4096 Nov 13 2011 daten drwxr-xr-x 15 root root 6400 Jul 28 07:29 dev drwxr-xr-x 81 root root 12288 Jul 28 07:29 etc drwxr-xr-x 6 root root 4096 Apr 15 10:20 home drwxr-xr-x 6 root root 4096 Nov 6 2011 lib drwx------ 2 root root 16384 Nov 4 2011 lost+found drwxr-xr-x 16 root root 4096 Jul 28 07:29 media drwxr-xr-x 10 root root 4096 Sep 26 2006 mnt drwxr-xr-x 7 root root 4096 Okt 26 2011 opt dr-xr-xr-x 172 root root 0 Jul 28 09:29 proc drwx--x--- 17 root root 4096 Nov 10 2011 root drwxr-xr-x 2 root root 12288 Jul 31 2011 sbin drwxr-xr-x 5 root root 4096 Nov 13 2011 sound drwxr-xr-x 2 root root 4096 Nov 6 2011 srv drwxr-xr-x 13 root root 0 Jul 28 09:29 sys drwxrwxrwt 13 root root 4096 Jul 28 13:21 tmp drwxr-xr-x 16 root root 4096 Mai 13 2011 usr drwxr-xr-x 18 root root 4096 Jul 28 2011 var bash-4.1$
Unter Linux existieren keine Laufwerksbuchstaben, der gesamte Verzeichnisbaum hat eine Wurzel / auf der root-Partition. In dieser root-Partition befinden sich die Verzeichnisse /etc, /bin, /sbin, /lib, /root, /dev, /proc und /sys, die der Kernel für den Systemstart zwingend benötigt. Es finden sich noch weitere Verzeichnisse, die ebenfalls Dateien und Verzeichnisse enthalten, oder die als Mountpoint für weitere Partitionen dienen. Alle Partitionen werden also zu einem gemeinsamen Verzeichnisbaum vereint, sodass der User im Prinzip überhaupt nicht merkt, auf welchen Massenspeicher er momentan zugreift. Egal ob es sich um eine Festplattenpartition, einen USB-Stick oder ein Netzlaufwerk handelt, alle Geräte werden vollkommen transparent in einem Verzeichnisbaum vereint. Dem System wird dabei in der Datei /etc/fstab mitgeteilt, welche Partitionen beim Systemstart an welcher Stelle des Verzeichnisbaums eingehängt (gemountet) werden sollen. Auch nach dem Systemstart ist es möglich, weitere Partitionen in den verzeichnisbaum zu mounten oder aus diesem wieder zu entfernen. Im Normalfall ist dazu jedoch nur root berechtigt, es gibt jedoch eine Reihe von Möglichkeiten, auch einem User das Recht einzuräumen, eine Partition (z.B. einen USB-Stick) zu mounten.
Die Verzeichnisse /proc, /dev und /sys enthalten das virtuelle Abbild des Kernels. Das Verzeichnis lost+found wird auf ext-Partitionen für fsck reserviert. Das Kommando fsck führt einen Check des Dateisystems durch. Dieser wird in regelm&aum;ßigen Abständen vor dem Mounten einer Partition veranlasst. Bei beschädigten Dateien werden noch rettbare Teile in diesem Verzeichnis abgelegt.Master-Boot-Record MBR
Im PC spielt der erste Block mit der Nummer 0 eine besondere Rolle, das ist der sogenannte Master-Boot-Record. Dieser ist von Bedeutung, wenn sich das Betriebssystem selbst auf der Festplatte befindet Nachdem der Rechner gestartet wurde und das Bios seine Selbsttest durchgeführt hat, sucht es nach einer Festplatte an der ersten Festplattenschnittstelle (IDE0, SATA0 , was auch immer) und liest diesen ersten Block von der Festplatte aus und läd ihn als Programmcode für den Prozessor in den RAM-Arbeitsspeicher, wo der Prozessor diesen maximal 512Byte langen Code ausführt. Dort, an dieser Stelle muss also der ausführbare Code eines Bootmanagers liegen, wie z.B. lilo oder grub. In diesem Code ist hinterlegt, in welchen Blöcken sich der Linux-Kernel befindet, mit welchen Optionen er gestartet wird und welches die root-Partition ist. Am Ende des MBR ist auch die Partitionstabelle der Festplatte gespeichert. Unter Umständen kann es sehr hilfreich sein, sich diesen MBR auf einem anderen Medium zu sichern, damit man ihn bei einem beschädigten Boot-Loader oder einem Verlust der Partitionstabelle leicht wieder herstellen kann. Mit den Kommandos dd und od kann root auf einfache Weise auf den MBR zugreifen. Hier mal ein Beispiel, wie man sich den MBR auf der Platte sda anschauen kann:
dd if=/dev/sda count=1| od -Ax -tx1z -v
Im terminal sieht das dann so aus:
bash-4.1# dd if=/dev/sda count=1 | od -Ax -tx1z -v
1+0 records in
1+0 records out
512 bytes (512 B) copied, 6.1452e-05 s, 8.3 MB/s
Adresse Speicherinhalt (hexadezimal) ASCII-Codierung
000000 fa eb 21 01 b4 01 4c 49 4c 4f 16 08 74 bc bb 4e >..!...LILO..t..N<
000010 00 00 00 00 99 e9 b3 4e 26 f0 26 f0 81 00 80 60 >.......N&.&....`<
000020 57 40 04 00 b8 c0 07 8e d0 bc 00 08 fb 52 53 06 >W@...........RS.<
000030 56 fc 8e d8 31 ed 60 b8 00 12 b3 36 cd 10 61 b0 >V...1.`....6..a.<
000040 0d e8 66 01 b0 0a e8 61 01 b0 4c e8 5c 01 60 1e >..f....a..L.\.`.<
000050 07 80 fa fe 75 02 88 f2 bb 00 02 8a 76 1e 89 d0 >....u.......v...<
000060 80 e4 80 30 e0 78 0a 3c 10 73 06 f6 46 1c 40 75 >...0.x.<.s..F.@u<
000070 2e 88 f2 66 8b 76 18 66 09 f6 74 23 52 b4 08 b2 >...f.v.f..t#R...<
000080 80 53 cd 13 5b 72 57 0f b6 ca ba 7f 00 42 66 31 >.S..[rW......Bf1<
000090 c0 40 e8 60 00 66 3b b7 b8 01 74 03 e2 ef 5a 53 >.@.`.f;...t...ZS<
0000a0 8a 76 1f be 20 00 e8 df 00 b4 99 66 81 7f fc 4c >.v.. ......f...L<
0000b0 49 4c 4f 75 29 5e 68 80 08 07 31 db e8 c9 00 75 >ILOu)^h...1....u<
0000c0 fb be 06 00 89 f7 b9 0a 00 b4 9a f3 a6 75 0f b0 >.............u..<
0000d0 02 ae 75 0a 06 55 b0 49 e8 cf 00 cb b4 40 b0 20 >..u..U.I.....@. <
0000e0 e8 c7 00 e8 b4 00 fe 4e 00 74 07 bc e8 07 61 e9 >.......N.t....a.<
0000f0 5c ff f4 eb fd 60 55 55 66 50 06 53 6a 01 6a 10 >\....`UUfP.Sj.j.<
000100 89 e6 53 f6 c6 60 74 70 f6 c6 20 74 14 bb aa 55 >..S..`tp.. t...U<
000110 b4 41 cd 13 72 0b 81 fb 55 aa 75 05 f6 c1 01 75 >.A..r...U.u....u<
000120 41 52 06 b4 08 cd 13 07 72 b4 51 c0 e9 06 86 e9 >AR......r.Q.....<
000130 89 cf 59 c1 ea 08 92 40 49 83 e1 3f 41 f7 e1 93 >..Y....@I..?A...<
000140 8b 44 08 8b 54 0a 39 da 73 92 f7 f3 39 f8 77 8c >.D..T.9.s...9.w.<
000150 c0 e4 06 86 e0 92 f6 f1 08 e2 89 d1 41 5a 88 c6 >............AZ..<
000160 eb 1c b4 42 5b bd 05 00 60 cd 13 73 16 4d 74 b8 >...B[...`..s.Mt.<
000170 31 c0 cd 13 61 4d eb f0 66 50 59 58 88 e6 b8 01 >1...aM..fPYX....<
000180 02 eb e1 8d 64 10 61 c3 66 ad 66 09 c0 74 0a 66 >....d.a.f.f..t.f<
000190 03 46 10 e8 5f ff 80 c7 02 c3 c1 c0 04 e8 03 00 >.F.._...........<
0001a0 c1 c0 04 24 0f 27 04 f0 14 40 60 bb 07 00 b4 0e >...$.'...@`.....<
0001b0 cd 10 61 c3 00 00 00 00 26 f0 26 f0 e1 b5 80 01 >..a.....&.&.....<
0001c0 01 00 83 fe 3f 7a 3f 00 00 00 7c 26 1e 00 00 00 >....?z?...|&....<
0001d0 01 7b 07 fe ff ff bb 26 1e 00 66 79 1a 06 00 fe >.{.....&..fy....<
0001e0 ff ff 82 fe ff ff 21 a0 38 06 f4 cf 3b 00 00 fe >......!.8...;...<
0001f0 ff ff 05 fe ff ff 15 70 74 06 84 ce a0 0c 55 aa >.......pt.....U.<
000200
bash-4.1#Hier ist der Hexadezimalabzug des ersten Blocks der Festplatte /dev/sda zu sehen. Auf der linken Seite sind in Türkis die Byteadressen aufgelistet. In der Mitte der inhalt der 512Bytes des MBR und auf der rechten Seite die Umsetzung der Zeichen in den ASCII-Code.
Zuerst fällt in der ersten Zeile das Wort LILO auf, denn im MBR ist der Bootmanager LILO installiert. In den ersten 440Bytes des MBR befindet sich der Binärcode des Bootmanagers. Danach folgt ab Adresse 0x01b8 der Disk-Identifier. Die Partitionstabelle ist ab Adresse 0x01be abgelegt. Die letzten zwei Bytes des Blockes enthalten die Magic Bytes 0x55 und 0xaa, die als Kennung für den MBR dienen.
Wird der MBR beschädigt oder gelöscht, kann das Betriebssystem nicht mehr starten und auch die Informationen über die Aufteilung der Festplatte in Partitionen sind weg. Sichern kann man sich den MBR ebenfalls mit dem Kommando dd, indem man einfach eine Datenstromumleitung benutzt und die 512Bytes in eine Datei umleitet.
Für diese Festplatte sieht das dann so aus:
dd if=/dev/sda count=1 > /tmp/MeinMBR
Diese Datei sollte man sich dann natürlich auf einem anderen Speichermedium ablegen, denn wenn ich diese Datei auf der Festplatte selbst abspeichere, dann komme ich ja bei einem zerstörten MBR nicht mehr an die Datei ;-). Um den MBR wieder zu restaurieren, könnte man auf dem Rechner ein Live-System starten und die Datei in den MBR zurückschreiben mit
dd if=/pfad/dateiname of=/dev/sda