Datenströme
- Datenstrommodell
- Datenausgabe
- Dateneingabe
- Datenverkettung durch Pipes
- Zeilenorientiertes Lesen von Standardin mit read
- Definition weiterer Datenkanäle mit exec
- Named Pipes
Durch die bash hat man mehrere Möglichkeiten, Daten aus einem Kommando oder Script an andere Kommandos oder Scripte zu übertragen. Die Syntax eines Befehls hat immer die selbe Form:
Die Angaben in den eckigen Klammern sind optional und können auch entfallen. Wichtig für die Betrachtungen hier sind die Umleitungsoperatoren.
Datenstrommodell
Um die Funktion der Shell zu verstehen, ist die Kenntnis des Datenstrommodells wichtig. Nach dem EVA-Prinzip, kann man sich die Funktionsweise von Programmen so vorstellen, dass sie Eingaben (E) entgegennehmen, diese Verarbeiten (V) und danach das Ergebnis ausgeben (A).
 Die Funktionsweise des Programms ist dabei durch Optionen (O) steuerbar und kann durch Parameter (P) beeinflusst werden, die dem Programm beim Aufruf mitgegeben werden.
Auf die Prozesse im Linuxsystem übertragen, sieht es nun so aus, dass jeder Prozess seine Daten aus Dateien einliest und die Ergebnisse in Dateien ausgibt.
Dazu benutzt man sogenannte Filedeskriptoren, die die Verbindung zu den jeweiligen Dateien darstellen.
Bei einem Filedescriptor handelt es sich um einen ganzzahligen Wert, beginnend mit 0.
Die Maximalzahl der Filedescriptoren richtet sich danach, welche Maximalzahl gleichzeitig geöffneter Dateien pro Prozess im Kernel eincompiliert wurde, meist sind es 1024.
Es sind dann alle Filedescriptoren von 0..1023 möglich.
(Solche Filedescriptoren werden in vielen Programmiersprachen mit dem Befehl open o.ä. geöffnet)
Die Funktionsweise des Programms ist dabei durch Optionen (O) steuerbar und kann durch Parameter (P) beeinflusst werden, die dem Programm beim Aufruf mitgegeben werden.
Auf die Prozesse im Linuxsystem übertragen, sieht es nun so aus, dass jeder Prozess seine Daten aus Dateien einliest und die Ergebnisse in Dateien ausgibt.
Dazu benutzt man sogenannte Filedeskriptoren, die die Verbindung zu den jeweiligen Dateien darstellen.
Bei einem Filedescriptor handelt es sich um einen ganzzahligen Wert, beginnend mit 0.
Die Maximalzahl der Filedescriptoren richtet sich danach, welche Maximalzahl gleichzeitig geöffneter Dateien pro Prozess im Kernel eincompiliert wurde, meist sind es 1024.
Es sind dann alle Filedescriptoren von 0..1023 möglich.
(Solche Filedescriptoren werden in vielen Programmiersprachen mit dem Befehl open o.ä. geöffnet)
Über diese Filedescriptoren erfolg der Datenaustausch der Prozesse, auf welche Datei der Filedescriptor zeigt, dafür ist die Shell zuständig.
Dadurch ist es für das einzelne Programm eigentllich unwesentlich, um welche Dateien es sich dabei handelt. Das Programm liest und schreibt in die Filediscriptoren und den Rest erledigen Shell und Kernel.
Wenn wir uns über ein Terminal (Textkonsole, was auch immer) am Linux-System angemeldet haben, wird eine interaktive Shell (hier also die bash) gestartet und damit man mit dem System kommunizieren kann, werden durch die Shell drei Filedescriptoren vordefiniert. Diese drei Filedescriptoren sind 0, 1 und 2, die als stdin (Standard-Input fd0), stdout (Standard-Output fd1) und stderr (Standard-Errorkanal fd2) bezeichnet werden. Diese drei Filedescriptoren benutzen alle Prozesse standardmäßig für ihre Datenein- und ausgabe, auch die interaktive Shell mit der wir nun arbeiten.
Deshalb hat die Shell diese drei Filedescriptoren mit der entsprechenden Gerätedatei verbunden, mit der der Kernel unser Terminal abbildet. Im Verzeichnis /dev sind alle angeschlossenen (echte oder virtuelle, egal) als Datei abgebildet und dort findet man drei Gerätedateien /dev/stdin, /dev/stdout und /dev/stderr. Das sind die drei "Geräte" mit denen der momentan laufende Prozess, also unsere interaktive Shell kommuniziert. Sie liest die Daten aus /dev/stdin und schreibt die Ausgaben nach /dev/stdout und eventuell auftretende Fehlermeldungen nach /dev/stderr.
Diese drei Gerätedateien sind symbolische Links, die (eventuell über weitere symbolische Links) auf die Gerätedatei das Terminals verweisen. Hier mal ein kleiner Auszug von einer virtuellen Textkonsole aus.bash-4.1$ ls -al /dev/std* lrwxrwxrwx 1 root root 15 Jul 27 12:06 /dev/stderr -> /proc/self/fd/2 lrwxrwxrwx 1 root root 15 Jul 27 12:06 /dev/stdin -> /proc/self/fd/0 lrwxrwxrwx 1 root root 15 Jul 27 12:06 /dev/stdout -> /proc/self/fd/1 bash-4.1$
Die drei Gerätedateien /dev/stdin, /dev/stdout und /dev/stderr zeigen in das proc-Verzeichnis des Kernels. Der Link /proc/self führt dabei in das Verzeichnis der laufenden bash (hier im Beispiel mit der PID 2667), also in das Verzeichnis /proc/2667 und dort in den Unterordner fd/ für die Filedescriptoren.
Schaut man sich diese genauer an, stellt man fest, auf welche Geräte sie verweisen:
bash-4.1$ ls -al /proc/self/fd/ insgesamt 0 dr-x------ 2 frank frank 0 Jul 27 12:06 . dr-xr-xr-x 7 frank frank 0 Jul 27 12:06 .. lrwx------ 1 frank frank 64 Jul 27 12:06 0 -> /dev/pts/1 lrwx------ 1 frank frank 64 Jul 27 12:06 1 -> /dev/pts/1 lrwx------ 1 frank frank 64 Jul 27 12:06 2 -> /dev/pts/1 lr-x------ 1 frank frank 64 Jul 27 12:06 3 -> /proc/2667/fd bash-4.1$
Die drei Filedescriptoren zeigen alle auf eine Gerätedatei /dev/pts/1. Bei den Gerätedateien unter /dev/pts/ handelt es sich um die Gerätedateien mit denen virtuelle Netzwerkterminals (hier xterm) abgebildet werden. Die bash liest also ihre Daten auf fd0 und damit aus der Datei /dev/pts/1 und schreibt die Ausgaben auf fd1, also in die Datei /dev/pts/1. Die Fehlermeldungen schreibt sie nach fd2 und damit ebenfalls in die Datei /dev/pts/1.
Die Datei /dev/pts/1 erzeugt der Kernel. Schickt unser Terminal einen Datenstrom an den Computer, dann kann dieser aus der Datei /dev/pts/1 gelesen werden. Werden Daten in die Datei /dev/pts/1 geschrieben, dann werden sie an unser Terminal gesendet.Je nachdem mit welchem Terminal man sich angemeldet hat, erscheint im Verzeichis /dev ein entsprechender eindeutiger Eintrag. Öffnet man z.B. jetzt weitere xterms, dann erscheinen weitere zusätzliche Dateien unter /dev/pts/, also /dev/pts/2, /dev/pts/3 .... usw. Oder sollte man ein virtuelles Textterminal benutzen, dann erscheinen dort Dateien unter /dev/vnc/. Oder wenn es ein echtes serielles Terminat ist, steht dort z.B. /dev/tty0 o.ä.
Um all dies müssen sich weder der Anwender noch der gestartete Prozess (Programm, Kommando) wirklich kümmern, das erledigen Shell und Kernel im Hintergrund. Der Prozess selbst muss sich nicht darum kümmern, wo die Datenquelle (Quelle des Datenstroms) und die Datensenke (Ziel der Datenausgabe) wirklich liegen, er verarbeitet nur den Datenstrom, der ihm an stdin angeboten wird und schafft die Ergebnisse nach stdout (und stderr).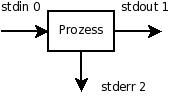 Den Prozessen werden durch die Shell standardmäßig drei Filedescriptoren stdin (fd0), stdout (fd1) und stderr(fd2) zur Verfügung gestellt.
Diese drei Datenkanäle zeigen in einer interaktiven Shell im Normalfall auf die Gerätedatei des Terminals, mit dem wir uns am System angemeldet haben und die Shell gestartet wurde.
Den Prozessen werden durch die Shell standardmäßig drei Filedescriptoren stdin (fd0), stdout (fd1) und stderr(fd2) zur Verfügung gestellt.
Diese drei Datenkanäle zeigen in einer interaktiven Shell im Normalfall auf die Gerätedatei des Terminals, mit dem wir uns am System angemeldet haben und die Shell gestartet wurde.
Durch diese Abstraktion aller Geräte, also sämtlicher Hardware auf eine Datei erreicht man nun, dass es den Kommandos oder Scripten prinzipiell egal ist, ob sie mit einer echten Datei auf einer Festplatte, einer Netzwerkschnittstelle, einem Terminal oder einer Soundkarte kommunizieren. Sie schreiben und lesen in Filedescriptoren, die die Shell erzeugt. Damit ist der Zugriff vollkommen hardwareunabhängig.
Wohin diese Kanäle nun letztendlich zeigen, legt die Shell fest. Durch spezielle Umleitungsoperatoren kann man sehr flexibel und einfach auch weitere Eingabe- und Ausgabekanäle definieren, über die der Prozess mit anderen Datenquellen und senken kommunizieren kann. Es ist auch ohne Probleme möglich, die drei Standardkanäle auf andere Dateien (also auch andere Hardware) umzulenken.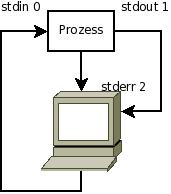 Hier haben wir nun also die Ausgangssituation:
Hier haben wir nun also die Ausgangssituation:
Befinden wir uns in einer Interaktiven-Loginshell, so sind die Datenkanäle 0, 1 und 2 standardmäßig durch die bash mit dem aufrufenden Terminal verbunden. Wenn wir nun einen Prozess starten, indem wir ein Kommando eingeben, dann übergibt die Shell die Verknüpfung der Datenkanäle 0,1 und 2 an die Arbeitsumgebung des gestarteten Prozesses sodass dieser ebenfalls mit unserem Terminal verbunden ist. Der Prozess liest also Eingaben aus stdin von der Tastatur unseres Terminals und damit landen die Tastatureingaben im Standardeingabekanal stdin des Prozesses. Da das Terminal im Normalfall so eingestellt ist, dass es die Eingabedaten erst nach einem <Enter> absendet, kann der Prozess die Daten auch erst dann empfangen. Es wird also nicht jede einzelne Tastatureingabe an den Prozess gesendet. Das ist von großem Vorteil, weil es zum einen die Bandbreite der Datenübertragung schont und Korrekturmöglichkeiten bei der Eingabe (backspace etc) auf das Terminal auslagert und so den Linuxrechner von simplen Eingabefunktionen befreit. Der Komfort bei der Editierung der Eingabe ist also komplett Sache des Terminals. Auf Wunsch kann man das Verhalten des Terminals aber ändern. Das nach (fast) jeder gedrückten Taste unserer Tastatur aber ein Zeichen auf dem Bildschirm erscheint ist keine Funktionalität der bash, sondern Ergebnis der aktivierten echo-Funktion des Terminals. Der Prozess selbst erfährt im Normalfall erst nach dem abschliessenden <Enter> von unseren Eingaben. Die Ausgaben des Prozesses auf stdout (Kanal 1) und stderr (Kanal 2) werden an das Terminal zurückgesendet und landen auf dem Bildschirm. Das bedeutet, dass die Ausgaben des Prozesses und seine Fehlermeldungen auf das gleiche Ziel geschrieben werden und deshalb auf dem Bildschirm vermischt werden. Diese Vermischung tritt nur ein, weil beide Kanäle auf die selbe Datensenke geleitet werden und deshalb fällt die Unterscheidung am Bildschirm manchmal schwehr. Trotzdem können und werden die Meldungen unterschiedlich behandelt und ausgewertet. Die Zuordung der Filedescriptoren hat also die folgende Form:
Die Besonderheit besteht nun darin, dass man diese Kanäle umleiten kann und so die Wege der Datenströme verändert werden.Datenkanäle des Prozesses Zieldescriptoren Datenkanal 0-stdin ← tty-out0 (Terminaltastatur) Datenkanal 1-stdout → tty-in1 (Terminalbildschirm) Datenkanal 2-stderr → tty-in2 (Terminalbildschirm) Datenausgabe
Die Ausgaben der Kommandos auf stdout landen also normalerweise auf dem Bildschirm unseres Terminals. Die bash bietet nun jedoch eine Reihe von Möglichkeiten, diesen Datenstrom umzuleiten. Am Beispiel des Kommandos echo sieht das dann so aus. Mit echo haben wir also eine einfache Möglichkeit, Daten über den Standardausgabekanal wieder auszugeben. Das echo-Kommando liest eine Reihe von Parametern und gibt sie über stdout wieder aus.
bash-2.05b$ echo "Hello World" Hello World bash-2.05b$
Datenkanäle des Prozesses Zieldescriptoren Datenkanal 0-stdin ← tty-out0 (Terminaltastatur) Datenkanal 1-stdout → tty-in1 (Terminalbildschirm) Datenkanal 2-stderr → tty-in1 (Terminalbildschirm) 
Wenn ich jetzt aber diese Ausgabe in eine Datei auf der Festplatte speichern will, dann bietet echo dafür keine Optionen. Es gibt eine Reihe von Kommandos in der Konsole, die weder aus einer Datei auf der Festplatte lesen, noch in eine solche Datei schreiben können. Das ist genaugenommen auch nicht notwendig, denn sie schreiben ihre Ausgabe ja schon in eine Datei, nämlich in die Datei, auf die der Filedescriptor 1 (stdout) zeigt. In den üblichen Programmiersprachen muss mit einem speziellen Befehl (z.B. open) ein Filedescriptor zum Schreiben in eine Datei geöffnet werden. Eine solche Möglichkeit sucht man in der Shell vergeblich. Der Grund dafür ist genauso einfach wie genial. Man überläßt diese Arbeit der Shell selbst und leitet die Datenströme der Kommandos, die über einen Ausgabekanal (z.B. Standardout) gesendet werden, einfach in eine andere Datei um. Man muss der Shell also beim Aufruf des Kommandos lediglich mitteilen, dass sie beim Erzeugen der Arbeitsumgebung des Kommandos den Filedescriptor 1 nicht auf die Gerätedatei des Terminals setzen soll, sondern auf eine andere Datei. Damit kann man durch eine einfache Umleitung die Ausgabe jedes Kommandos z.B. in Dateien ablegen, ohne dass das Kommando selbst diese Funktionalität besitzen muss. Dazu kennt die bash eine Reihe von Umleitungszeichen. Die "Hello World"-Ausgabe soll nun nicht auf dem Bildschirm landen, sondern in die Datei /tmp/test1.text geschrieben werden. Dafür bietet die Shell das Umleitungszeichen >, das an das echo-Kommando angehängt wird. Genau genommen müsste das Umleitungszeichen eigentlich 1> sein, aber der Umleitungsoperator > ist eine zulässige Kurzschreibweise, da der stdout-Datenkanal 1 sehr oft umgeleitet wird. Durch diese Umleitung zeigt der Datenkanal 1(stdout) nicht mehr auf das Terminal, weshalb die Meldungen nicht auf dem Bildschirm, sondern in der Datei /tmp/test1.text landen. Alle anderen Datenkanäle behalten ihre Zuordnungen bei. Eventuelle Fehlermeldungen von echo landen weiterhin auf dem Bildschirm, denn diese werden auf stderr gesendet und der zeigt weiterhin auf das Terminal.
bash-2.05b$ echo "Hello World" > /tmp/test1.text bash-2.05b$
Datenkanäle des Prozesses Zieldescriptoren Datenkanal 0-stdin ← tty-out0 (Terminaltastatur) Datenkanal 1-stdout → /tmp/test1.text Datenkanal 2-stderr → tty-in2 (Terminalbildschirm) 
Auf dem Bildschirm erscheint keinerlei Ausgabe, denn durch den Umleitungsoperator > wird der Datenstrom des Ausgabekanals in die Datei /tmp/test1.text umgeleitet und erscheint deshalb nicht mehr in unserem Terminal. Sollte die Datei vorher noch nicht existiert haben, so wird sie durch die Shell angelegt. Wenn die Datei vorher schon existiert hat, wird der alte Inhalt der Datei überschrieben und geht verloren. Das Schreiben in die Datei funktioniert natürlich nur, wenn der Benutzer über die entsprechenden Rechte verfügt. Ansonsten erzeugt die Shell eine Fehlermeldung und bricht das Kommando ab.
Mit dem Kommando cat können wir schnell nachschauen, was in der Datei /tmp/test1.text gespeichert ist. Das cat-Kommando liest der Inhalt der Datei und gibt ihn auf stdout aus.bash-2.05b$ cat /tmp/test1.text Hello World bash-2.05b$
Beim Aufruf des Kommandos echo "Hello World" > /tmp/test1.text hat die Shell also die Arbeitsumgebung für den echo-Prozess erzeugt, die Verknüpfung ihrer Filedescriptoren 0, 1 und 2 in diese übergeben und den Filedescriptor 1 manipuliert, indem dieser jetzt nicht mehr auf die Terminal-Gerätedatei zeigt, sondern auf eine Datei /tmp/test1.text auf der Festplatte. Wichtig ist, dass die Arbeitsumgebung des echo-Prozesses manipuliert wurde, nicht die der Shell selbst. Für die Shell ändert sich also nichts, deshalb meldet sie sich nach dem Ende des echo-Kommandos auch wieder auf dem Terminalbildschirm zurück. Da die Arbeitsumgebung des echo-Prozesses manipuliert wurde und diese nach Beendigung des Prozesses immer vernichtet wird, übernimmt wieder die Shell mit ihren Ausgabeumleitungen auf unser Terminal.
Ein weiterer wichtiger Umleitungsoperator ist >>. Er funktioniert genauso wie >, nur wird der Inhalt der Datei nicht überschrieben, sondern die Ausgabe an das Ende der Datei angehängt.
bash-2.05b$ echo "noch ein Hello" >> /tmp/test1.text bash-2.05b$ cat /tmp/test1.text Hello World noch ein Hello
Datenkanäle des Prozesses Zieldescriptoren Datenkanal 0-stdin ← tty-out0 (Terminaltastatur) Datenkanal 1-stdout → /tmp/test1.text Datenkanal 2-stderr → tty-in2 (Terminalbildschirm) Wird dem Umleitungoperator > keine Zahl mitgegeben, so interpretiert die Shell dies als 1>, dh. es wird stdout umgeleitet. Wird vor dem Operator > eine Zahl mitgegeben, so kann man auch andere Ausgabekanäle (z.B. mit 2> der Standard-Fehlerkanal) umleiten.
Nehmen wir an, wir wollen mehrere Dateien (in diesem Fall nur zwei) mit cat nacheinander ausgeben und das Ergebnis in einer neuen Datei /tmp/test2.text speichern. Die beiden Dateien sollen /tmp/test1.text und die nicht existierende Datei /tmp/gibtsnicht sein. Wenn wir das Kommando cat /tmp/test1.text /tmp/gibtsnicht dazu in der Konsole aufrufen, ergibt sich folgendes Ergebnis:
bash-3.1$ cat /tmp/test1.text /tmp/gibtsnicht Hello World noch ein Hello cat: /tmp/gibtsnicht: Datei oder Verzeichnis nicht gefunden bash-3.1$
Datenkanäle des Prozesses Zieldescriptoren Datenkanal 0-stdin ← tty-out0 (Terminaltastatur) Datenkanal 1-stdout → tty-in1 (Terminalbildschirm) Datenkanal 2-stderr → tty-in2 (Terminalbildschirm) Da noch keine Umleitung definiert wurde, landen alle Ausgaben, sowohl stdout als auch stderr auf dem Bildschirm unseres Terminals. Fügen wir jetzt die Umleitung des Datenstroms mit 1>/tmp/test2.text oder einfach nur >/tmp/test2.text mit an, dann sieht das so aus:
bash-3.1$ cat /tmp/test1.text /tmp/gibtsnicht 1> /tmp/test2.text cat: /tmp/gibtsnicht: Datei oder Verzeichnis nicht gefunden bash-3.1$
Datenkanäle des Prozesses Zieldescriptoren Datenkanal 0-stdin ← tty-out0 (Terminaltastatur) Datenkanal 1-stdout → /tmp/test2.text Datenkanal 2-stderr → tty-in2 (Terminalbildschirm) Wenn wir nachschauen, werden wir sehen, dass die Datei /tmp/test2.text nun existiert und dass sie den entsprechenden Text aus Datei test1.text enthält, denn die zweite Datei konnte ja nicht geöffnet werden. Die Fehlermeldung dazu landet weiterhin auf unserem Terminal, denn die wurde ja nicht umgeleitet.
Wir können die Fehlermeldung ebenfalls in eine Datei umleiten, dazu benutzen wir den Umleitungsoperator 2>/tmp/fehlermeldungen.bash-3.1$ cat /tmp/test1.text /tmp/gibtsnicht 1> /tmp/test2.text 2> /tmp/fehlermeldungen bash-3.1$
Datenkanäle des Prozesses Zieldescriptoren Datenkanal 0-stdin ← tty-out0 (Terminaltastatur) Datenkanal 1-stdout → /tmp/test2.text Datenkanal 2-stderr → /tmp/fehlermeldungen Da nun keiner der beiden Datenkanäle 1 und 2 auf das Terminal zeigt, erfolgt auch keine Ausgabe von cat auf dem Terminalbilschirm. Dafür befindet sich nun der Dateiinhalt von /tmp/test1.text in der Datei /tmp/test2.text und die Fehlermeldung "cat: /tmp/gibtsnicht: Datei oder Verzeichnis nicht gefunden" befindet sich wie gewünscht in der Datei /tmp/fehlermeldungen.
Und nun leiten wir beide Datenkanäle in die selbe Datei /tmp/test2.text um. Man könnte nun meinen, dass das mit cat /tmp/test1.text /tmp/gibtsnicht 1> /tmp/test2.text 2> /tmp/test2.text geht. Im Grunde genommen stimmt das auch, aber wenn man sich das Ergebnis anschaut wird man feststellen, dass sich nur die Fehlermeldung in der Datei findet.bash-3.1$ cat /tmp/test1.text /tmp/gibtsnicht 1> /tmp/test2.text 2> /tmp/test2.text bash-3.1$ cat /tmp/test2.text cat: /tmp/gibtsnicht: Datei oder Verzeichnis nicht gefunden bash-3.1$
Datenkanäle des Prozesses Zieldescriptoren Datenkanal 0-stdin ← tty-out0 (Terminaltastatur) Datenkanal 1-stdout → /tmp/test2.text Datenkanal 2-stderr → /tmp/test2.text Der Grund liegt darin, dass zwei Filedescriptoren geöffnet werden, die beide in eine leere (oder noch nicht vorhandene) Datei schreiben und den eventuell vorher existierenden Inhalt der Datei löschen. Also wird zuerst über einen Filedescriptor die stdout-Ausgabe von cat in die Datei /tmp/test2.text geschrieben und der alte Inhalt der Datei geht verloren. Damit landet der Inhalt der Datei /tmp/test1.text in der Datei /tmp/test2.text. Danach entsteht beim Öffnen der Datei /tmp/gibtsnicht eine Fehlermeldung, und die wird über den zweiten Filedescriptor in die selbe Datei geöoffnet und damit der vorherige Inhalt überschrieben. Damit geht der bis dahin von stdout geschriebene Inhalt verloren. Man kann sich das sehr schön ansehen, indem man das Kommando noch etwas abändert und drei Dateien durch cat ausgeben lässt.
bash-3.1$ cat /tmp/test1.text /tmp/gibtsnicht /tmp/test1.text 1> /tmp/test2.text 2> /tmp/test2.text bash-3.1$ cat /tmp/test2.text cat: /tmp/gibtsnicht: Datei oder Verzeichnis nicht gefunden Hello World bash-3.1$
Zuerst erfolgt die Ausgabe des Inhaltes der Datei /tmp/test1.text auf stdout, dazu wird die Datei /tmp/test2.text geöffnet und der alte Inhalt überschrieben. Danach gibt es beim Lesen der Datei /tmp/gibtsnicht eine Fehlermeldung auf stderr. Dazu wird die Datei /tmp/test2.text nun ebenfalls geöffnet und der alte Inhalt überschrieben. Deshalb geht der zuvor in die Datei /tmp/test2.text geschriebene Inhalt verloren. Nun wird die Datei /tmp/test1.text durch cat nochmals gelesen und über stdout ausgegeben. Über den Filedescriptor 1 ist die Datei /tmp/test2.text ja bereits geöffnet und damit landet der Inhalt auch dort. Der zuerst ausgegebene Inhalt der Datei /tmp/test1.text befindet sich deshalb nicht in der datei /tmp/test2.text, sondern nur die Fehlermeldung und die zweite Ausgabe der datei /tmp/test1.text
Sinnvoller ist es daher, der bash zu sagen, dass beide Kanäle über den selben Filedescriptor umgeleitet werden sollen, dann wird die Datei beim erstmaligen Schreiben geöffnet und beide Kanäle schreiben über den gemeinsamen Filedescriptor in die Datei /tmp/test2.text. Das geht mit dem Umleitungsoperator 2>&1. Dieser besagt, dass der Datenkanal 2 sich den Filedescriptor kopiert, den Datenkanal 1 momentan hat. Da die bash die Umleitungsoperatoren von links nach rechts abarbeitet, muss der Umleitungsoperator 2>&1 also für unser Beispiel nach dem Umleitungsoperator 1> /tmp/test2.text eingefügt werden, damit der Datenkanal 1 erst einmal einen Filedescriptor auf die Datei /tmp/test2.txt erhält und sich der Datenkanal 2 sich diesen dann kopiert. Das komplette Kommando lautet dann: cat /tmp/test1.text /tmp/gibtsnicht 1> /tmp/test2.text 2>&1.bash-3.1$ cat /tmp/test1.text /tmp/gibtsnicht 1> /tmp/test2.text 2>&1 bash-3.1$ cat /tmp/test2.text Hello World noch ein Hello cat: /tmp/gibtsnicht: Datei oder Verzeichnis nicht gefunden bash-3.1$
Datenkanäle des Prozesses Zieldescriptoren Datenkanal 0-stdin ← tty-out0 (Terminaltastatur) Datenkanal 1-stdout → /tmp/test2.text Datenkanal 2-stderr Hier wird jetzt also zuerst der Datenkanal 1 (stdout) auf die Datei /tmp/test2.text umgeleitet. Danach kopiert sich Datenkanal 2 (stderr) den Filedescriptor den Datenkanal 1 jetzt hat und zeigt damit in den selben Filedescriptor wie stdout, nämlich in die Datei /tmp/test2.text.
Würde man die beiden Umleitungsoperatoren in der Reihenfolge vertauschen, also das Kommando cat /tmp/test1.text /tmp/gibtsnicht 2>&1 1> /tmp/test2.text eingeben, so würde folgendes passieren.bash-3.1$ cat /tmp/test1.text /tmp/gibtsnicht 2>&1 1> /tmp/test2.text bash-3.1$ cat /tmp/test2.text Hello World noch ein Hello cat: /tmp/gibtsnicht: Datei oder Verzeichnis nicht gefunden bash-3.1$
Datenkanäle des Prozesses Zieldescriptoren Datenkanal 0-stdin ← tty-out0 (Terminaltastatur) Datenkanal 1-stdout → /tmp/test2.text Datenkanal 2-stderr → tty-in1 Zuerst würde der Datenkanal 2 (stderr) sich den Filedescriptor kopieren, den Datenkanal 1 (stdout) gerade benutzt, das ist tty-in, also unser Terminalkanal 1 auf den Bildschirm und danach würde Datenkanal 1 des Kommandos cat eine Umleitung in die Datei bekommen. Die Ausgabe von cat würde also in der Datei /tmp/test2.text landen und die Fehlermeldung über Datenkanal1 der bash auf unserem Bildschirm.
Das könnte z.B. sinnvoll sein, wenn man die Daten in die Datei transportieren möchte und die Fehlermeldung in einer Variable gespeichert werden soll. Da mit der Kommandosubstitution $( kommando ) nur die Ausgaben auf Datenkanal 1 (stdout) abgefangen werden, kann man so die Fehlermeldung auffangen.bash-3.1$ A="$( cat /tmp/test1.text /tmp/gibtsnicht 2>&1 1> /tmp/test2.text )" bash-3.1$ echo $A cat: /tmp/gibtsnicht: Datei oder Verzeichnis nicht gefunden bash-3.1$
Datenkanäle des Prozesses Zieldescriptoren Datenkanal 0-stdin ← tty-out (Terminaltastatur) Datenkanal 1-stdout → /tmp/test2.text Datenkanal 2-stderr → tty-in1 → VAR A Wichtig ist noch, das die Umleitung prinzipiell in jede Art von Datei möglich ist. Das bedeutet auch in Gerätedateien (z.B. auf die serielle Schnittstelle /dev/ttyS0) oder in Netzwerkverbindungen. Genaueres siehe man bash.
Dateneingabe
Am Beispiel des echo-Kommandos haben wir nun zwei einfache Möglichkeiten der Umleitung von Ausgabekanälen kennengelernt. Mindestens genauso wichtig ist die Dateneingabe, damit ein Script Daten entgegennehmen und verarbeiten kann, bevor sie dann wieder ausgegeben werden können. Viele Kommandos bieten die Möglichkeit, einen Dateinamen anzugeben, aus denen die Daten gelesen werden. Wird kein solcher Dateiname angegeben, so lesen die Kommandos im allgemeinen von stdin. Das kann man z.B. am Kommando cat sehen. Genau genommen liest cat den Datenstrom an stdin und gibt diesen an stdout wieder aus. Vorhin haben wir dem Kommando cat einen Dateinamen mitgegeben, und damit hat cat dann die Daten aus dieser Datei gelesen. Wenn wir nun keinen Dateinamen angeben, wartet cat auf Daten an stdin. Also geben wir in der Konsole einfach mal cat ein.
bash-2.05b$ cat
Es passiert scheinbar nichts und der Prompt kehrt auch nicht wieder zurück. Das cat-Kommando wartet nun auf Daten am Eingabekanal stdin, dieser ist momentan mit unserer Tastatur verbunden. Also geben wir nun einfach "Hello World" ein und schliessen mit der Entertaste ab. Das Drücken der Entertaste ist notwendig, da in den aktuellen Einstellungen des Terminals der Text erst nach Enter abgesendet wird und damit an stdin von cat ankommt.
bash-2.05b$ cat Hello World Hello World
Sofort nach dem Drücken der Entertaste erscheint die Ausgabe auf unserem Bildschirm und cat wartet auf weitere Daten. Weitere Eingaben landen nun ebenfalls über stdout auf unserem Bildschirm.
bash-2.05b$ cat Hello World Hello World noch ein Hello noch ein Hello
Das geht so lange, bis cat ein EOF (End of File) erkennt, das können wir in unserem Terminal z.B. mit <Strg>+<D> auslösen. Das cat-Kommando beendet sich und der Prompt kehrt zurück.
Als kleine Demonstration, was man mit den Umleitungen der Datenkanäle erreichen kann, hier zwei Beispiele. Wir legen eine Datei an, die einen Text enthält und werden eine Sicherungskopie der Datei anfertigen. Zum Anlegen der Datei benötigen wir keinen Editor, sondern benutzen einfach cat, wobei wir die Ausgaben in eine Datei umleiten. Das Kommando cat liest den Datenstrom von stdin, der von unserer Tastatur stammt, bis wir die Eingabe mit <Strg>+<D> beenden. Die Ausgabe von cat auf stdout leiten wir mit dem Umleitungsoperator > in die Datei /tmp/test2.text um. Der Text soll wieder nur "Hello World" sein, könnte aber natürlich auch mehrere Zeilen umfassen. Danach muss noch ein Enter gedrückt werden, damit das Terminal den String auch absendet und danach <Strg>+<D>, damit cat auch das Ende des Datenstroms erkennt.bash-2.05b$ cat > /tmp/test2.text Hello World bash-2.05b$
Vielleicht fällt jemandem hier ein scheinbarer Widerspruch auf. Da unsere Tastatureingaben nach stdin von cat geleitet werden und die Ausgaben von cat in die Datei /tmp/test2.text gehen, warum erscheinen dann unsere Tastatureingaben auf dem Bildschirm? Die Ursache liegt in der bereits oben beschriebenen Eigenschaft unseres Eingabeterminals, das im Normalfall mit eingeschalteter echo-Funktion läuft. Das bedeutet, dass sämtliche Tastatureingaben durch das Terminal selbst sofort auf dem Bildschirm ausgegeben werden. Die Einstellungen kann man mit dem Kommando stty -a einsehen, dort steht echo ohne vorangestelltes -, was bedeutet, dass die echo-Funktion eingeschaltet ist. Wer das testen will, kann die echo-Funktion gern mit stty -echo abschalten, nur muss er dann alle Kommandos blind eingeben, da ja nur die Ausgaben der Kommandos auf unserem Bildschirm landen. Die echo-Funktion des Terminals wird z.B. bei der Passworteingabe abgeschaltet. Man sollte die echo-Funktion also wieder mit stty echo aktivieren, denn so lässt sich etwas besser arbeiten :-)
Nun zurück zum Thema. Mit cat können wir uns nun davon überzeugen, dass der Text wirklich in der Datei gespeichert wurde.bash-2.05b$ cat /tmp/test2.text Hello World bash-2.05b$
So, nun zur Sicherungskopie. Der Inhalt der Datei /tmp/test2.text soll in eine Datei /tmp/test3.text kopiert werden. Das können wir einmal mit einer einfachen Ausgabeumleitung erreichen, indem wir cat den Dateinamen /tmp/test2.text mitteilen. Die Datei wird geöffnet und der Inhalt auf stdout ausgegeben, den wir in die Datei /tmp/test3.text umleiten.
bash-2.05b$ cat /tmp/test2.text > /tmp/test3.text bash-2.05b$
Eine weitere interessante Möglichkeit ist die Umleitung von stdin, sodass der Datenstrom nicht mehr von unserer Tastatur stammt, sondern aus einer Datei. Das bewerkstelligt der Umleitungsoperator <.
bash-2.05b$ cat < /tmp/test2.text Hello World bash-2.05b$
Durch diesen Umleitungsoperator verbindet die bash den Dateneingang stdin des Kommandos cat mit der Datei /tmp/test2.text. Es werden nun also nicht mehr die Tastatureingaben an den stdin von cat geleitet, sondern der Dateiinhalt von /tmp/test2.text. Nun muss nur die Ausgabe auf stdout ebenfalls umgeleitet werden und die Datei wird somit kopiert.
bash-2.05b$ cat < /tmp/test2.text > /tmp/test3.text bash-2.05b$
Die bash wird nun also das Kommando cat starten, durch die Umleitung "< /tmp/test2.text" den Inhalt der Datei /tmp/test2.text an den Dateneingabekanal stdin senden. Die Ausgaben des Kommandos cat werden durch die Umleitung "> /tmp/test3.text" in die Datei /tmp/text3.txt geschickt. Da die Umleitungen eine Funktionalität der bash sind, funktioniert das mit den anderen Kommandos in ähnlicher Weise. Bleibt noch zu bemerken, dass die Befehlszeile /tmp/test2.text > cat > /tmp/test3.text zu einer Fehlermeldung führt, da die bash in einer Befehlszeile an erster Stelle den Kommandonamen erwartet.
Wie leistungsfähig die Umleitungsmechanismen der Shell sind, soll mit einem kleinen Beispiel verdeutlicht werden. Der folgende Einzeiler ist im Prinzip ein Mini-Webbrowser, der die Startseite von google.de anfordert und den HTML-Quellcode der Seite auf dem Terminal ausgibt.
Der Befehl lautet: (echo -ne "GET http://www.google.de/index.html HTTP/1.0 \n\n" 1>&0 ; cat ) <> /dev/tcp/www.google.de/80
Wenn der Rechner direkten Internetkontakt hat (nicht über einen Proxy!) und einen DNS kontaktieren kann, erscheint nach der Eingabe ein Wust von HTML-Zeichen, die den Inhalt der Google-Startseite darstellen.
Eine kurze Erklärung zu dem Einzeiler:( ........ ) <> /dev/tcp/www.google.de/80 Mit dem Kontrolloperator () wird eine Subshell geöffnet. Das bedeutet, das in der Shell eine weitere Shell gestartet wird, in der mehrere Kommandos ausgeführt werden, die dann alle über die umgeleiteten Datenkanäle der Subshell kommunizieren können. Mithilfe des R/W-Umleitungsoperators <> wird auf dem Datenkanal 0 (stdin) eine Schreib- und Leseverbindung über einen TCP-Socket auf das Netzwerk geöffnet. Es wird der Host www.google.de auf dem TCP-Port 80 (http) kontaktiert. Alle Ausgaben der Subshell auf Datenkanal 0 (stdin) werden an den Host www.google.de über das Netzwerk umgeleitet und alle Ausgaben des Hosts www.google.de landen auf Datenkanal 0 (stdin) der Subshell.
echo -ne "GET http://www.google.de/index.html HTTP/1.0 \n\n" 1>&0 ; Mit dem echo innerhalb der Subshell wird die Anfrage an den Webserver erstellt. Ein Webserver erwartet von einem Webbrowser einen String, der bei einer Get-Anfrage mit GET beginnt, gefolgt von der URL der gewünschten Datei. Die Angabe HTTP/1.0 teilt dem Webserver lediglich mit, welchen HTML-Standard der Browser versteht. Die Anfrage wird mit einem Zeilenumbruch \n und einer Leerzeile \n abgeschlossen. Die Ausgabe von echo wird mit 1>&0 auf den selben Filedescriptor wie Datenkanal 0 (stdin) umgeleitet und geht damit über die Netzwerkverbindung der Subshell an den Google-Server.
cat Das cat-Kommando erwartet nun einfach einen Datenstrom von stdin in der Subshell, also in diesem Fall vom Webserver und gibt ihn an Datenkanal 1 (stdout) wieder aus. Da stdout nicht umgeleitet wurde, landen die Ausgaben der Subshell auf dem Terminalbildschirm. Prinzipiell könnte man die cat-Ausgabe innerhalb der Subshell mit cat > /tmp/googleindex.html auch in eine Datei umleiten und hätte diese dann auf seiner Festplatte. Das geht natürlich auch mit allen anderen Dateien (Bilder, MP3 etc) so.
Mit diesem kleinen Scriptstück ist man also in der Lage, eine beliebige Datei aus dem Internet herunterzuladen und das in einem Textterminal und ohne Zusatzsoftware, einfach mit der Shell.
bash-2.05b$ (echo -ne "GET http://www.google.de/index.html HTTP/1.0 \n\n" >&0 ; cat ) <> /dev/tcp/www.google.de/80 HTTP/1.0 200 OK Date: Sat, 02 Jul 2011 11:08:15 GMT Expires: -1 Cache-Control: private, max-age=0 Content-Type: text/html; charset=ISO-8859-1 Set-Cookie: PREF=ID=24b7309b4b6ecca6:FF=0:TM=1309604895:LM=1309604895:S=6fvnmaBWxkTepoIj; expires=Mon, 01-Jul-2013 11:08:15 GMT; path=/; domain=.google.de Set-Cookie: NID=48=NTg8isAQaFdwVoId4kepj3AaEI_15OWYc8ZVS8pRltYDDSOMQDrwuCzCOvHtkI7f17eC0qSx1yKuGCzGjXtJO5ioY639H1ZDFUNiFMmlzDzmvieHifCPxbrfbMAjGoel; expires=Sun, 01-Jan-2012 11:08:15 GMT; path=/; domain=.google.de; HttpOnly Server: gws X-XSS-Protection: 1; mode=block <!doctype html><html><head><meta http-equiv="content-type" content="text/html; charset=ISO-8859-1"><title>Google</title><script>window.google={kEI:"H_wOTqOLItSAswaMiJHSDQ",kEXPI:"28505,28936,30316,30465,31091,31116,31259",kCSI:{e:"28505,28936,30316,30465,31091,31116,31259",ei:"H_wOTqOLItSAswaMiJHSDQ",expi:"28505,28936,30316,30465,31091,31116,31259"},authuser:0,ml:function(){},kHL:"de",time:function(){return(new Date) ..... bash-2.05b$Datenverkettung durch Pipes
Die Datenkanäle mehrerer Kommandos können durch sogenannte Pipes miteinander verbunden werden. Eine Pipe wird in der bash durch den Operator ¦ erzeugt. Eine Pipe verbindet den Standardausgabekanal stdout eines Kommandos mit dem Standardeingabekanal stdin des folgenden Kommandos. Dadurch wird erreicht, das die Ausgaben des ersten Kommandos durch das folgende Kommando weiter verarbeitet werden können.
Dazu ein Beispiel.
Es soll eine Liste der IP-Adressen aller Netzwerkgeräte erzeugt werden, die im System aktiv sind. Auskunft über die Netzwerkschnittstellen soll das Kommando ifconfig geben. Also geben wir in unsere Konsole /sbin/ifconfig ein.bash-2.05b$ /sbin/ifconfig lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 UP LOOPBACK RUNNING MTU:16436 Metric:1 RX packets:319 errors:0 dropped:0 overruns:0 frame:0 TX packets:319 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:589003 (575.1 Kb) TX bytes:589003 (575.1 Kb) tap0 Link encap:Ethernet HWaddr 00:FF:E0:EF:64:BF inet addr:10.0.0.208 Bcast:10.0.0.255 Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:12450 errors:0 dropped:0 overruns:0 frame:0 TX packets:12066 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:100 RX bytes:7569658 (7.2 Mb) TX bytes:1506105 (1.4 Mb) wlan0 Link encap:Ethernet HWaddr 00:E0:98:E2:95:98 inet addr:192.168.1.208 Bcast:192.168.1.255 Mask:255.255.255.0 UP BROADCAST NOTRAILERS RUNNING MULTICAST MTU:1500 Metric:1 RX packets:20826 errors:3 dropped:0 overruns:0 frame:0 TX packets:13921 errors:7 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:5659759 (5.3 Mb) TX bytes:2529460 (2.4 Mb) Interrupt:9 bash-2.05b$Es erscheint eine mehr oder weniger lange Liste mit den konfigurierten Netzwerkgeräten, die eine Reihe von Angaben zu den Einstellungen enthält. Aus dieser Liste interessieren uns nur die IP-Adressen, die hinter "inet addr:" angegeben sind. Es müssen nun also alle Zeilen aus der Ausgabe von ifconfig herausgesucht werden, die den String "inet addr:" enthalten. Das erreichen wir mit dem Kommando grep, dem wir den Suchbegriff mitgeben. Das grep-Kommando erwartet an stdin den zu durchsuchenden Datenstrom, den es Zeilenweise abarbeitet. Dazu leiten wir jetzt die Ausgabe von /sbin/ifconfig nach stdin von grep um, indem wir eine Pipe legen. Damit landet die Ausgabe von /sbin/ifconfig nicht mehr auf unserem Bildschirm, sondern in der Eingabe von grep. Das wiederum wird den Datenstrom durchsuchen und alle Zeilen, die den text "inet addr:" enthalten an stdout ausgeben, was dann auf unserem Bildschirm zu sehen ist.
bash-2.05b$ /sbin/ifconfig | grep "inet addr:" inet addr:127.0.0.1 Mask:255.0.0.0 inet addr:10.0.0.208 Bcast:10.0.0.255 Mask:255.255.255.0 inet addr:192.168.1.208 Bcast:192.168.1.255 Mask:255.255.255.0 bash-2.05b$So, nun muss aus der Ausgabe noch die IP-Adresse selbst ausgeschnitten werden. Das besorgt das Kommando cut. Dieses Kommando teilt den Datenstrom an stdin in einzelne Teile (Felder) auf, wobei z.B. ein Trennzeichen mit -d definiert werden kann. Die einzelnen Felder werden durchnummeriert und können dadurch gezielt ausgegeben werden. Das Kommando cut arbeitet ebenfalls zeilenorientiert. Wir lassen den Datenstrom am Doppelpunkt aufteilen und damit befindet sich die gewünschte IP-Adresse im 2.Feld. Die cut-Befehlszeile lautet also cut -d: -f2. Da cut nun die Ausgabe von grep verarbeiten soll, hängen wir das Kommando mit einer weiteren Pipe an grep an.
bash-2.05b$ /sbin/ifconfig | grep "inet addr:" | cut -d: -f2 127.0.0.1 Mask 10.0.0.208 Bcast 192.168.1.208 Bcast bash-2.05b$
Nun stören nur noch die Anhängsel und das erledigen wir mit einem weiteren cut. Trennzeichen ist das Leerzeichen und das erste Feld wird ausgegeben.
bash-2.05b$ /sbin/ifconfig | grep "inet addr:" | cut -d: -f2 | cut -d' ' -f1 127.0.0.1 10.0.0.208 192.168.1.208 bash-2.05b$
Fertig. Über die Eleganz dieser Lösung kann man sich streiten, aber es sollte lediglich die Funktionsweise einer Pipe demonstriert werden :-)
Entscheidend ist, das durch die Pipes mehrere Kommandos miteinander zu einer Liste verkettet werden können, sodass jedes Kommando wie ein Filter die Ausgabe des vorhergehenden weiter bearbeitet, bis letztendlich die gewünschte Information herausgefiltert ist. Um diesen Mechanismus nutzen zu können ist es wichtig, das die Kommandos und auch selbst erstellte Scripte ihre Daten von stdin lesen können. Die volle Tragweite der Datenstromumleitung in eine Datei oder aus einer Datei heraus wird klar, wenn man sich bewußt mach, dass in Linux gilt:"Alles ist eine Datei!". So werden z.B. im Verzeichnis /dev Pseudo-Dateien erzeugt, mit denen der Kernel den Zugriff auf die Hardware regelt und im Verzeichnis /proc sehen wir die Schnittstelle zum Kernel selbst und hier sind auch lauter Dateien.Zeilenorientiertes Lesen von Standardin mit read
Innerhalb eines Scriptes möchte man nun die Eingaben über stdin verarbeiten. Dazu ist es oft sinnvoll, die Daten in einer Variable zu speichern und mit Hilfe von cat und der Kommandosubstitution der bash ist das auch möglich. In einem Script test könnte das wie folgt aussehen:
#!/bin/bash echo "Bitte geben Sie Ihren Namen ein:" NAME=$( cat ) echo "Guten Tag lieber ${NAME} !"Wenn wir dieses Script ausführbar machen und starten, dann erwartet es nach der ersten Ausgabe eine Eingabe an stdin (also momentan von der Tastatur), die wir mit Enter und <Strg>+<D> abschliessen. Es erscheint die gewünschte Ausgabe. Wir können die Eingabe auch durch eine Pipe tätigen, also z.B. mit echo "Walter" | ./test.
Diese Methode des Lesens von stdin hat jedoch mehrere Nachteile.- Sie ist nicht besonders bedienerfreundlich, denn jede Eingabe über die Tastatur ist mit Enter und <Strg>+<D> zu beenden. Das kann schnell nerven.
- Bei mehreren Eingaben auf diese Art und Weise gibt es Probleme mit der Pipe, da der Datenstrom bei der ersten Eingabe ja schon sein EOF absenden muss.
- Wenn das Script in einer Pipe liegt und das vorherige Kommando sehr große Datenmengen ausgibt, werden diese erst einmal komplett eingelesen und in der Variable zwischengespeichert, bevor das Script weiter ausgeführt wird. Das kann sehr schnell zu Speicherproblemen führen.
- Wenn der Eingabedatenstrom unendlich ist (zb aus einem fortlaufenden Logfile gelesen wird), wird das Kommando cat nie beendet und das Script hängt.
Das Kommando read ist hier eine effiziente Alternative. Im Normalfall liest das Kommando read eine Eingabezeile von Standardin, die mit Enter (Zeilenschaltung <newline>) abgeschlossen wird. Die eingelesenen Daten werden in einer oder mehreren Variablen oder einem Array abgelegt. Die Eingabe wird im Normalfall mit <newline> beendet. Hier ein paar Beispiele:
#!/bin/bash read TESTA echo "Die Variable TESTA enthält $TESTA" read -p "Bitte geben Sie Ihren Namen ein: " NAME echo "Die Variable NAME enthält $NAME" read -s -p "Bitte geben Sie Ihr Passwort ein: " PASSWORT echo echo "Die Variable PASSWORT enthält $PASSWORT" echo -n "Bitte geben Sie Ihren Vor- und Zunamen ein: " read VNAME ZNAME DUMMY echo "Der Vorname ist $VNAME, der Nachname ist $ZNAME, die restlichen Eingaben sind $DUMMY" echo "Welches sind Ihre Liebligsspeisen? " read -a ESSEN echo "Das Array ESSEN enthaelt folgende Elemente ${ESSEN[*]}" read -t 10 -p ">" WERT echo "Der exit-status der letzten read-Anweisung ist $?" echo "Die Variable WERT enthaelt $WERT" read -p "Alles klar?" echo "Die Variable REPLY enthaelt $REPLY"Die Scriptzeilen haben folgende Bedeutungen.
Zuerst liest ein read die komplette Eingabe und speichert sie in der Variablen TESTA ab. Die Eingabe kann aus keinem, einem oder mehreren Worten bestehen, die Eingabe wird mit <newline> abgeschlossen. Anschliessend erfolgt die Ausgabe mit echo.
Das näste read verwendet die Option -p um einen Erläuterungstext auf Standarderr auszugeben. Die Eingabe wird in der Variablen NAME gespeichert.
In der dritten read-Anweisung wird mit der Option -s (silent-mode) erreicht, das die eingegebenen Zeichen nicht wieder im Terminalschirm angezeigt werden, das Passwort also verdeckt bleibt. Da auch das abschließende <newline> nicht auf dem Bildschirm erscheint, wird mit einem einfachen echo eine Zeilenschaltung erzeugt.
Danach erfolgt die Benutzerführung nicht durch die Option -p, sondern durch eine vorherige Ausgabe des Erläuterungstextes durch echo. Der read-Anweisung werden die drei Variablen VNAME, ZNAME und DUMMY mitgegeben. read trennt die Eingabe anhand der Trennungszeichen (Leerzeichen, Tabulator je nach dem Inhalt der Shellvariable IFS) in einzelne Worte auf. Das erste eingegebene Wort wird in VNAME, das zweite Wort in ZNAME und der ganze, eventuell zuviel eingegebene Rest, in DUMMY abgespeichert.
In der fünften read-Anweisung kommt nun ein Array zum Einsatz. Mit der Option -a wird read mitgeteilt, das es die Eingabe in Worte splitten soll und diese fortlaufend ab Index 0 (Null) in dem Array ESSEN abspeichern soll. Wenn das Array noch nicht existiert, so wird es durch diese Anweisung angelegt und entsprechend der Eingabe gefüllt. Sollte das Array bereits existiert haben, dann gehen alle vorher darin abgelegten Inhalte verloren.
Die nächste read-Anweisung benutzt die Option -t um einen Timeout festzulegen. read wartet 10 Sekunden lang auf die Eingabe der Daten. Wird diese nicht innerhalb der Zeit vollständig abgeschlossen, so bricht read mit einem Fehler ab, die Variable WERT ist dann leer. Der exit-status 1 meldet diesen Fehler. Wurde die Eingabe rechtzeitig beendet, so wird diese in WERT abgespeichert und der exit-status ist 0 (Null).
In der letzten read-Anweisung wurde keine Variable zum Abspeichern der Eingabe angegeben. In diesem Fall speichert read das Ergebnis in der Shellvariable REPLY ab.
Die Terminalausgabe zu dem Script könnte so aussehen:bash-2.05b$ ./test Hallo, wer da? Die Variable TESTA enthält Hallo, wer da? Bitte geben Sie Ihren Namen ein: frank Die Variable NAME enthält frank Bitte geben Sie Ihr Passwort ein: Die Variable PASSWORT enthält brotkorb Bitte geben Sie Ihren Vor- und Zunamen ein: Frank Häßler noch was Der Vorname ist Frank, der Nachname ist Häßler, die restlichen Eingaben sind noch was Welches sind Ihre Liebligsspeisen? Brot Butter und Käse Das Array ESSEN enthaelt folgende Elemente Brot Butter und Käse Der exit-status der letzten read-Anweisung ist 1 Die Variable WERT enthaelt Alles klar?ja Die Variable REPLY enthaelt ja bash-2.05b$
Definition weiterer Datenkanäle mit exec
Die Shell stellt uns die drei Statdardkanäle 0 stdin, 1 stdout und 2 stderr zur Verfügung. Es ist jedoch leicht möglich, sich weitere Datenkanäle erzeugen zu lassen. Das geschieht mit dem Kommando exec.
Befehl Erläuterung exec 3> /tmp/test3.text Öffnet den Datenkanal 3 mit einem überschreibenden Filedescriptor auf die Datei /tmp/test3.text exec 4>> /tmp/test2.text Öffnet den Datenkanal 4 mit einem anhängenden Filedescriptor auf die Datei /tmp/test2.text exec 5< /tmp/test1.text Öffnet den Datenkanal 5 mit einem lesenden Filedescriptor auf die Datei /tmp/test1.text exec 6<> /tmp/test4.text Öffnet den Datenkanal 6 mit einem Filedescriptor zum gleichzeitigen Lesen und Schreiben in die Datei /tmp/test3.text exec 3&>- Schliesst den Datenkanal 3 wieder. Named Pipes
Die oben beschriebene Pipe verkettet mehrere Prozesse, indem sie den Datenausgang stdout mit dem Dateneingang stdin des Kindprozesses miteinander verbindet. Mit diesen Pipes können also nur Prozesse kommunizieren, die von selben Elternprozess stammen. Linux ist aber ein Multitasking-Betriebssystem auf dem gleichzeitig viele Prozesse laufen, die auch von vielen unterschiedlichen Usern stammen können. Wenn eine Kommunikation zwischen diesen Prozessen gewünscht ist, dann nützen diese Pipes nichts.
Eine Möglichkeit wäre es, eine Datei zu vereinbaren, auf die beide Prozesse Zugriff haben (Rechte setzen!) und auf diese dann lesend und schreibend zugreifen und dadurch Daten miteinander austauschen. Diese Methode hat jedoch Nachteile:- Der lesende Prozess hat keinerlei Informationen, wann er Daten erhät, das bedeutet, dass er ständig oder in gewissen zeitabstä,nden den inhalt der Datei kontrollieren muss.
- Der schreibende Prozess hat ohne weitere Vereinbarungen keine Information darüber, ob die Daten denn nun gelesen wurden oder nicht.
Auf einem Linux-System sind zwei User angemeldet und arbeiten an ihren Terminals. Der User frank erzeugt eine Named-Pipe /tmp/pipe und vergibt die Rechte so, dass er die Pipe schreiben und lesen darf und alle User nur lesen, alle Anderen dürfen nichts ;-).
Danach wird ein echo gestartet und die Ausgabe in die Pipe umgeleitet.bash-4.1$ rm /tmp/pipe bash-4.1$ mkfifo /tmp/pipe bash-4.1$ ls -al /tmp/pipe prw-r--r-- 1 frank frank 0 Jul 28 12:13 /tmp/pipe bash-4.1$ chgrp users /tmp/pipe bash-4.1$ chmod o= /tmp/pipe bash-4.1$ ls -al /tmp/pipe prw-r----- 1 frank users 0 Jul 28 12:18 /tmp/pipe bash-4.1$ echo "Hallo" 1> /tmp/pipe
Das echo-Kommando hängt nun, da noch kein lesender Prozess auf die Pipe zugreift.
Nun öffnet der User karl auf seinem terminal ein cat und leitet die Pipe auf stdin um. Damit wird die Pipe gelesen und in diesem Moment sendet echo seine Daten ab und cat empfägt sie und beide Prozesse beenden sich.bash-4.1$ cat 0< /tmp/pipe Hallo bash-4.1$
Die Daten wurden von einem Prozess zu einem anderen Prozess übertragen.